transformer-词嵌入和位置嵌入详解
文章目录
- 1、介绍一下位置嵌入Positional Encoding、什么是Positional Encoding呢?为什么Transformer需要Positional Enconding? Transformer 的 Positional Encoding 是如何表达相对位置关系的?
- 2、我来简单举个例子
- 2.1 词向量:每个token都会被映射为词向量
- 2.2 位置嵌入
- 3、对位置编码公式中2i和2i+1的进一步解释
1、介绍一下位置嵌入Positional Encoding、什么是Positional Encoding呢?为什么Transformer需要Positional Enconding? Transformer 的 Positional Encoding 是如何表达相对位置关系的?
答: 一句话概括,Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
Attention 对位置不敏感的原因,因此其无法捕捉到输入序列中 token 的位置信息。一种可行的办法就是在输入的时候加入每个 token 的位置信息。
首先, 在任何一门语言中,词语的位置和顺序对句子意思表达都是至关重要的。 传统的RNN模型在处理句子时,以序列的模式逐个处理句子中的词语,这使得词语的顺序信息在处理过程中被天然的保存下来了,并不需要额外的处理。 而对于Transformer来说,由于句子中的词语都是同时进入网络进行处理,顺序信息在输入网络时就已丢失。因此,Transformer是需要额外的处理来告知每个词语的相对位置的。 其中的一个解决方案,就是论文中提到的Positional Encoding,将能表示位置信息的编码添加到输入中,让网络知道每个词的位置和顺序。
作者:月球上的人
链接:https://zhuanlan.zhihu.com/p/338592312
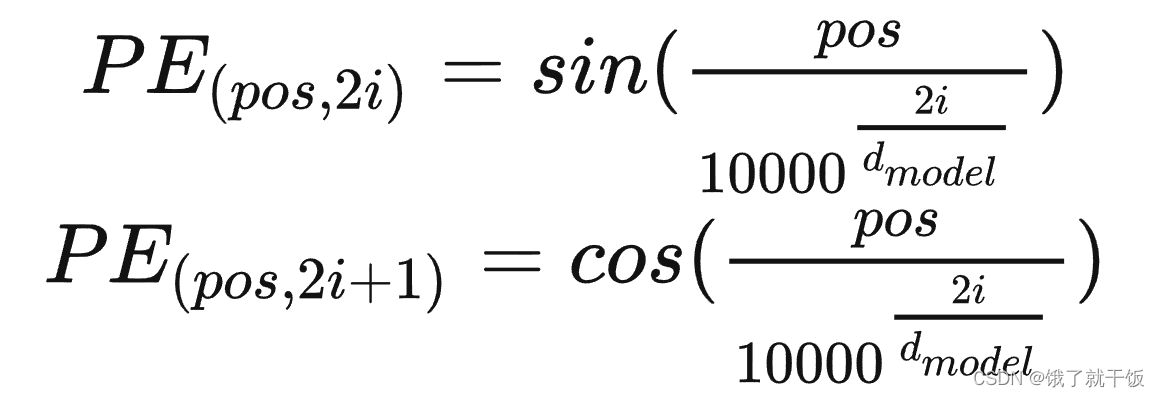
Transformer 摈弃了 RNN 的结构,因此需要一个东西来标记各个字之间的时序 or 位置关系,而这个东西,就是位置嵌入。作者为此设计了一种Positional Encoding,首先,它不是一个数字,而是一个包含句子中特定位置信息的d维向量。其次,这种嵌入方式没有集成到模型中,相反,这个向量是用来给句子中的每个字提供位置信息的,换句话说,我们通过注入每个字位置信息的方式,增强了模型的输入(其实说白了就是将位置嵌入和字嵌入相加,然后作为输入)
pos表示token在sequence中的位置,位置编码的公式中的i表示的是第i个 position embedding 维度(即你看哈,pm要被表示为一个向量哈,这个向量呢每个维度都得有值吧,它是怎么控制那个分母上的指数呢,就是靠每个维度在向量中的索引的变形,具体变形还是看上面那个图片里的公式,有了这个i之后就可以控制这个向量里的每两个值使用的是同一个分母)
上图以及pos和i的含义解释参考:解释 Transformer 中的绝对位置编码(这个文章吊炸天,太强了!!!)
2、我来简单举个例子
我爱北京天安门
分词:我、爱、北京、天安门
2.1 词向量:每个token都会被映射为词向量
我 e0--->[1,2,2,4]
爱 e1--->[0,2,6,3]
北京 e2--->[8,0,7,5]
天安门 e3--->[9,2,8,1]
2.2 位置嵌入
按上面的公式计算,那就是会出现4个位置嵌入
我 , 爱 , 北京 , 天安门 我,爱,北京,天安门 我,爱,北京,天安门
p 0 , p 1 , p 2 , p 3 p_0, p_1, p_2, p_3 p0,p1,p2,p3
每个位置嵌入的维度是4,令
p 0 = [ x 0 , x 1 , x 2 , x 3 ] p_0=[x0,x1,x2,x3] p0=[x0,x1,x2,x3]
那么x0:
x 0 = s i n ( m 1000 0 2 ∗ i d ) = s i n ( 0 1000 0 2 ∗ 0 4 ) x_0 = sin(\frac{m}{10000^\frac{2*i}{d}})=sin(\frac{0}{10000^\frac{2*0}{4}}) x0=sin(10000d2∗im)=sin(1000042∗00)
其中:
m=0,即“我”在句子“我爱北京天安门”中是处于第0个位置
i=0,即现在是计算的“我”的位置嵌入的第0维度是多少值,则i=0
d=4,即嵌入向量的维度
那么x1:
x 1 = c o s ( m 1000 0 2 ∗ i d ) = c o s ( 0 1000 0 2 ∗ 1 4 ) x_1 = cos(\frac{m}{10000^\frac{2*i}{d}})=cos(\frac{0}{10000^\frac{2*1}{4}}) x1=cos(10000d2∗im)=cos(1000042∗10)
其中:
m=0,即“我”在句子“我爱北京天安门”中的位置
i=1,即现在是计算的“我”的位置嵌入的第1维度
d=4,即嵌入向量的维度
那么x2:
x 2 = s i n ( m 1000 0 2 ∗ i d ) = s i n ( 0 1000 0 2 ∗ 2 4 ) x_2 = sin(\frac{m}{10000^\frac{2*i}{d}})=sin(\frac{0}{10000^\frac{2*2}{4}}) x2=sin(10000d2∗im)=sin(1000042∗20)
其中:
m=0,即“我”在句子“我爱北京天安门”中是处于第0个位置
i=2,即现在是计算的“我”的位置嵌入的第2维度是多少值
d=4,即嵌入向量的维度
那么x3:
x 3 = c o s ( m 1000 0 2 ∗ i d ) = c o s ( 0 1000 0 2 ∗ 3 4 ) x_3 = cos(\frac{m}{10000^\frac{2*i}{d}})=cos(\frac{0}{10000^\frac{2*3}{4}}) x3=cos(10000d2∗im)=cos(1000042∗30)
其中:
m=0,即“我”在句子“我爱北京天安门”中是处于第0个位置
i=3,即现在是计算的“我”的位置嵌入的第3维度是多少值
d=4,即嵌入向量的维度
那么
p 0 = ( s i n ( m 1000 0 2 ∗ i d ) , c o s ( m 1000 0 2 ∗ i d ) , s i n ( m 1000 0 2 ∗ i d ) , c o s ( m 1000 0 2 ∗ i d ) ) = ( s i n ( 0 1000 0 2 ∗ 0 4 ) , c o s ( 0 1000 0 2 ∗ 1 4 ) , s i n ( 0 1000 0 2 ∗ 2 d ) , c o s ( 0 1000 0 2 ∗ 3 4 ) ) = ( s i n 0 , c o s 0 , s i n 0 , c o s 0 ) = ( 0 , 1 , 0 , 1 ) \begin{aligned} p_0&= (sin(\frac{m}{10000^\frac{2*i}{d}}),cos(\frac{m}{10000^\frac{2*i}{d}}),sin(\frac{m}{10000^\frac{2*i}{d}}),cos(\frac{m}{10000^\frac{2*i}{d}}))\\ &=(sin(\frac{0}{10000^\frac{2*0}{4}}),cos(\frac{0}{10000^\frac{2*1}{4}}),sin(\frac{0}{10000^\frac{2*2}{d}}),cos(\frac{0}{10000^\frac{2*3}{4}}))\\ &=(sin0,cos0,sin0,cos0)\\ &=(0,1,0,1)\\ \end{aligned} p0=(sin(10000d2∗im),cos(10000d2∗im),sin(10000d2∗im),cos(10000d2∗im))=(sin(1000042∗00),cos(1000042∗10),sin(10000d2∗20),cos(1000042∗30))=(sin0,cos0,sin0,cos0)=(0,1,0,1)
那么”我的“输入:
e 0 + p 0 = [ 1 , 2 , 2 , 4 ] + [ 0 , 1 , 0 , 1 ] = ( 1 , 3 , 2 , 5 ) \begin{aligned} e_0+p_0 &=[1,2,2,4]+[0,1,0,1]\\ &=(1,3,2,5)\\ \end{aligned} e0+p0=[1,2,2,4]+[0,1,0,1]=(1,3,2,5)
这还只是计算了“我”的Embedding,还有“爱”,“北京”,“天安门”的Embedding没有写出来,稍后我来写出来。
3、对位置编码公式中2i和2i+1的进一步解释
不用追求2i和2i+1的值到底是多少,只需认识到,2i是偶数,2i+1是奇数
还有一个重要的话:上面的公式中2i和2i+1指的是词语向量中,每个维度的位置
举例:我的词向量表示:
[5, 8.3, 24, 31, 90, 55, 48]
词向量中的每个数字的位置下标为:
[0, 1, 2, 3, 4, 5, 6]
那么位置下标表示为奇偶的表示:
[2i+1,2i,2i+1,2i,2i+1,2i,2i+1,2i,2i+1]
所以用
[sin,cos,sin,cos,sin,cos,sin] # 这里就可以看到奇数索引的用sin,偶数索引用cos
来计算位置向量