LangChain4j(7):Springboot集成LangChain4j实现知识库RAG
我们之前的直接整合进SpringBoot进行实战,最终其实还会将查询到的内容,和对话上下文组合起来,发给LLM为我们组织语言进行回答:
- 配置一个Content Retriever 内容检索器,提供向量数据库和向量模型及其他参数
- 将内容检索器绑定到AiServices
- 当我们进行LLM对话时,底层会自动为我们检索向量数据库进行回答
基于之前的springboot进行添加:
在Aiconfig中添加Assistant:
public interface Assistant{String chat(String message);// 流式响应TokenStream stream(String message);}@Beanpublic EmbeddingStore embeddingStore() {return new InMemoryEmbeddingStore();}@Beanpublic Assistant assistant(ChatLanguageModel qwenChatModel,StreamingChatLanguageModel qwenStreamingChatModel,ToolsService toolsService,EmbeddingStore embeddingStore,QwenEmbeddingModel qwenEmbeddingModel) {// 对话记忆ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);// 内容检索器ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder().embeddingStore(embeddingStore).embeddingModel(qwenEmbeddingModel).maxResults(5) // 最相似的5个结果.minScore(0.6) // 只找相似度在0.6以上的内容.build();// 为Assistant动态代理对象 chat ---> 对话内容存储ChatMemory----> 聊天记录ChatMemory取出来 ---->放入到当前对话中Assistant assistant = AiServices.builder(Assistant.class).tools(toolsService).contentRetriever(contentRetriever).chatLanguageModel(qwenChatModel).streamingChatLanguageModel(qwenStreamingChatModel).chatMemory(chatMemory).build();return assistant;}添加端口代码:
@RequestMapping(value = "/memory_stream_chat",produces ="text/stream;charset=UTF-8")public Flux<String> memoryStreamChat(@RequestParam(defaultValue="我是谁") String message, HttpServletResponse response) {TokenStream stream = assistant.stream(message);return Flux.create(sink -> {stream.onPartialResponse(s -> sink.next(s)).onCompleteResponse(c -> sink.complete()).onError(sink::error).start();});}由于是测试,我们直接将代码存放到缓存,但是在实际开发中建议将代码存放的向量数据库中,这边Springboot的启动类中添加代码:
@BeanCommandLineRunner ingestTermOfServiceToVectorStore(EmbeddingStore embeddingStore,QwenEmbeddingModel qwenEmbeddingModel){return args -> {Document document = ClassPathDocumentLoader.loadDocument("rag/terms-of-service.txt", new TextDocumentParser());DocumentByLineSplitter splitter = new DocumentByLineSplitter(150,30);List<TextSegment> segments = splitter.split(document);// 向量化List<Embedding> embeddings = qwenEmbeddingModel.embedAll(segments).content();// 存入embeddingStore.addAll(embeddings,segments);};}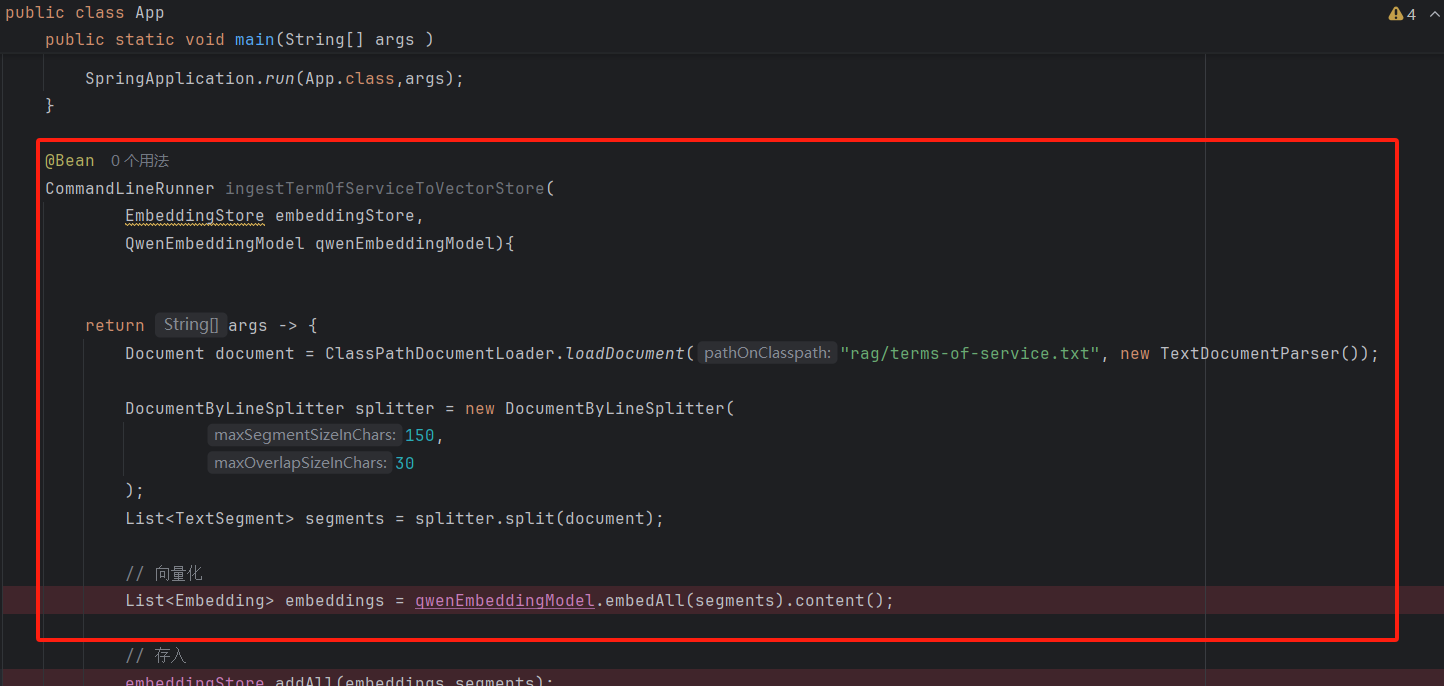
测试后运行结果如下: