DMA 概念与讲解

文章目录
- 一、Linux 物理内存区
- 1. 硬件限制与 DMA 兼容性
- 2. 各个 ZONE 的作用
- ZONE_DMA(直接内存访问区)
- ZONE_NORMAL(普通内存区)
- ZONE_HIGHMEM(高端内存区)
- 3. 内存分配策略
- 连续物理内存分配(`kmalloc`)
- 非连续内存分配(`vmalloc`)
- Slab 分配器与对象缓存
- 4. 跨架构差异
- 二、PCIe 的 DMA 内存寻址范围
- 1. PCIe 规范的地址空间
- 2. 系统架构的影响
- 32 位系统
- 64 位系统
- 3. 关键硬件组件
- PCIe 控制器(Root Port)
- 设备自身的 DMA 引擎
- 4. Linux 内核的 DMA 管理
- DMA 地址掩码设置
- Bounce Buffer 机制
- 5. 实际限制示例
- 三、反弹缓冲区(Bounce Buffer)
- 1. 核心原理
- (1) 工作流程
- 2. 优缺点分析
- 3. 代码示例(Linux内核)
- 四、PCIe DMA 传输过程详解
- 从操作系统分配 DMA 内存
- 将 DMA 地址编程到设备并开始传输
- 设备执行 DMA 事务
- 五、USB Root Hub DMA 传输
- 1. usb_hcd_map_urb_for_dma
- (1)、函数功能概述
- (2)、代码逻辑详解
- 1. 控制传输处理
- 2. 数据传输处理
- 3. 错误处理与资源释放
- (3)、核心设计思想
- (4)、关键数据结构与标志
- (5)、典型调用场景
- (6)与 URB 生命周期的关系
- (7)总结
- 2、hcd_alloc_coherent
- (1)、函数功能与设计目标
- 1. 核心功能
- 2. 设计目标
一、Linux 物理内存区
Linux 内核将物理内存划分为 ZONE_DMA、ZONE_NORMAL 和 ZONE_HIGHMEM 的原则,主要基于以下核心因素:
1. 硬件限制与 DMA 兼容性
-
传统 DMA 控制器:
老旧设备(如 ISA 总线设备)的 DMA 控制器仅支持 低物理地址范围(如 0x00000000 ~ 0x00FFFFFF,即 16MB)。此时必须使用 ZONE_DMA(通常对应物理地址 0x00000000 ~ 896MB),否则 DMA 操作会失败。 -
现代 DMA 控制器:
新硬件(如 PCIe 设备)通常支持 32 位或 64 位全地址范围,理论上可以直接访问 ZONE_NORMAL 的物理内存(如 0x80000000 ~ 0x7FFFFFFFFF)。但需确保设备驱动明确支持此类操作。
2. 各个 ZONE 的作用
ZONE_DMA(直接内存访问区)
- 目的:支持老旧 DMA 控制器(Direct Memory Access)的硬件设备。
- 硬件限制:
许多早期 DMA 控制器(如 ISA 总线设备)仅能访问物理地址的低范围(通常为 0x00000000 ~ 0x00FFFFFF,即 16MB 或更低)。
若设备 DMA 操作超出此范围,可能导致地址溢出或数据损坏。 - 内核策略:
将物理内存的低地址段(如0x00000000 ~ 896MB)保留为 ZONE_DMA,确保 DMA 设备可直接访问。
ZONE_NORMAL(普通内存区)
- 目的:存放内核核心数据和频繁访问的内存。
- CPU 架构优化:
现代 CPU 的 MMU(内存管理单元)和缓存机制对低端内存的访问效率更高。
内核代码、页表、全局数据结构(如task_struct)需稳定且连续的物理内存,因此优先分配 ZONE_NORMAL。
ZONE_HIGHMEM(高端内存区)
- 目的:解决 32 位系统的物理内存寻址限制。
- 32 位系统限制:
32 位系统的虚拟地址空间为 4GB,内核直接映射的物理内存范围通常为0x00000000 ~ 0x7FFFFFFF(即 896MB)。
超出部分(>896MB)无法直接映射到内核虚拟地址空间,需通过动态映射(如vmalloc或kmap)访问,这部分称为 ZONE_HIGHMEM。 - 64 位系统差异:
64 位系统的虚拟地址空间极大(如 128TB),可直接映射全部物理内存,因此 无需 ZONE_HIGHMEM。
3. 内存分配策略
连续物理内存分配(kmalloc)
- ZONE_DMA & ZONE_NORMAL:
kmalloc()分配的物理内存默认来自 ZONE_DMA 或 ZONE_NORMAL,保证连续性和低延迟,适用于 DMA、内核数据结构等场景。若指定GFP_DMA标志,内核会 强制从 ZONE_DMA 分配。如果未显式指定GFP_DMA,内核可能从 ZONE_NORMAL 分配内存。此时需满足两个条件:- 物理地址连续:DMA 操作需要连续的物理内存。
- 设备支持全地址范围:DMA 控制器必须能访问 ZONE_NORMAL 的物理地址。
非连续内存分配(vmalloc)
- ZONE_HIGHMEM(32 位):
vmalloc()分配的虚拟内存可能映射到 ZONE_HIGHMEM,但物理页不要求连续,适用于大块内存或无需 DMA 的场景。
Slab 分配器与对象缓存
- 缓存亲和性:
频繁访问的小对象(如struct page)优先从 ZONE_NORMAL 分配,减少缓存失效。
| 分配器 | 虚拟地址范围 | 物理地址连续性 | 适用场景 |
|---|---|---|---|
| kmalloc | 内核直接映射区 | 连续 | DMA、硬件操作、内核数据结构 |
| vmalloc | VMALLOC_START ~ VMALLOC_END | 不连续 | 大块虚拟内存(无需物理连续) |
| kmem_cache | 内核直接映射区 | 连续 | 小对象复用(如 struct page) |
4. 跨架构差异
| 系统架构 | ZONE_DMA | ZONE_NORMAL | ZONE_HIGHMEM |
|---|---|---|---|
| 32 位 | 低端内存(如 0~16MB) | 中段内存(16MB~896MB) | 高端内存(>896MB) |
| 64 位 | 通常空闲或极小 | 覆盖几乎全部物理内存 | 不存在 |
二、PCIe 的 DMA 内存寻址范围
PCIe 的 DMA 支持的内存寻址范围取决于 硬件设计、系统架构 和 操作系统配置。以下是其核心机制和限制的详细分析:
1. PCIe 规范的地址空间
-
理论最大地址范围:
PCIe 协议规定总线地址为 64 位宽,理论上支持 16EB(Exabytes) 的物理地址空间。
但实际可用范围受限于设备硬件、控制器和操作系统的实现。 -
默认地址宽度:
大多数 PCIe 设备默认支持 32 位地址(4GB),高端设备(如 NVMe SSD、GPU)可能支持 64 位地址。
2. 系统架构的影响
32 位系统
- 物理地址限制:
32 位系统的物理地址空间为 4GB,但通过 PAE(Physical Address Extension) 可扩展到 64GB(36 位)。- DMA 地址范围:
- 若设备仅支持 32 位地址,DMA 缓冲区必须位于
0x00000000 ~ 0xFFFFFFFF内。 - 在 Linux 中可通过
dma_set_mask()设置设备支持的地址掩码(如DMA_BIT_MASK(32)或DMA_BIT_MASK(36))。
- 若设备仅支持 32 位地址,DMA 缓冲区必须位于
- DMA 地址范围:
64 位系统
- 几乎无地址限制:
64 位系统的物理地址空间可达 128TB(48 位物理寻址),高端设备(如 x86-64 CPU)通常支持 40/48/57 位物理地址。- DMA 地址范围:
- 若设备支持 64 位地址,DMA 缓冲区可覆盖几乎全部物理内存。
- 需通过
dma_set_mask()启用 64 位地址支持(如DMA_BIT_MASK(64))。
- DMA 地址范围:
3. 关键硬件组件
PCIe 控制器(Root Port)
- 地址转换能力:
PCIe 控制器需支持地址转换(如 IOMMU),将设备的 DMA 地址映射到系统物理地址。- IOMMU 的作用:
在启用 IOMMU(如 Intel VT-d、AMD-Vi)时,设备 DMA 地址可以是虚拟地址,由 IOMMU 动态映射到物理内存。
- IOMMU 的作用:
设备自身的 DMA 引擎
- 设备限制:
某些老旧设备(如早期 SATA 控制器)可能仅支持 32 位 DMA 地址,需通过dma_set_coherent_mask()强制约束。
4. Linux 内核的 DMA 管理
DMA 地址掩码设置
- 驱动中的典型操作:
// 启用 64 位 DMA 支持 pci_set_dma_mask(pdev, DMA_BIT_MASK(64)); if (dma_set_mask(&pdev->dev, DMA_BIT_MASK(64))) {dev_warn(&pdev->dev, "Failed to set 64-bit DMA mask");return -EIO; }
Bounce Buffer 机制
- 地址不匹配时的处理:
若设备的 DMA 地址范围不足,内核会分配一个 反弹缓冲区(Bounce Buffer),将数据从高端内存复制到设备可访问的低端地址。- 性能影响:反弹缓冲区会增加数据拷贝开销。
5. 实际限制示例
| 场景 | DMA 地址范围 | 操作系统支持 |
|---|---|---|
| 老旧 PCIe 设备(32 位) | 0x00000000 ~ 0xFFFFFFFF | Linux 内核默认支持 |
| 现代 NVMe SSD(64 位) | 0x00000000 ~ 0x7FFFFFFFFFFF(48 位) | 需启用 IOMMU 和 64 位 DMA mask |
| GPU(64 位地址) | 0x0000000000000000 |
三、反弹缓冲区(Bounce Buffer)
DMA反弹缓冲区(Bounce Buffer)是解决 DMA设备与CPU内存访问地址不兼容问题 的关键技术,其核心目标是通过中间缓冲区实现数据的安全传输。以下是其原理、实现细节及应用场景的深度解析:
1. 核心原理
(1) 工作流程
- 数据复制:将原始缓冲区(不可访问区域)的数据复制到反弹缓冲区(设备可访问区域)。
- DMA传输:设备通过反弹缓冲区完成数据读写。
- 反向复制(可选):若需将数据返回给原始缓冲区,需再次复制。
2. 优缺点分析
| 优点 | 缺点 |
|---|---|
| ✔️ 解决硬件地址限制问题 | ❌ 额外内存复制开销 |
| ✔️ 支持非连续内存传输 | ❌ 增加延迟(尤其大数据量时) |
| ✔️ 简化驱动开发(抽象底层细节) | ❌ 需管理缓冲区生命周期(分配/释放) |
3. 代码示例(Linux内核)
// 分配反弹缓冲区
void *bounce_buf = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL);// 将数据从原始缓冲区复制到反弹缓冲区
memcpy(bounce_buf, original_buf, size);// 配置DMA传输目标地址为反弹缓冲区的物理地址
dma_map_single(dev, bounce_buf, size, DMA_TO_DEVICE);// 触发DMA传输
dmaengine_submit(desc);
dma_async_issue_pending(chan);// 传输完成后同步数据回原始缓冲区(若需要)
dma_sync_single_for_cpu(dev, dma_handle, size, DMA_FROM_DEVICE);
memcpy(original_buf, bounce_buf, size);// 释放资源
dma_free_coherent(dev, size, bounce_buf, dma_handle);
四、PCIe DMA 传输过程详解
PCIe MMIO、DMA、TLP
【PCIe】PCIe配置空间与CPU访问机制
从操作系统分配 DMA 内存
将 DMA 地址编程到设备并开始传输
原始数据
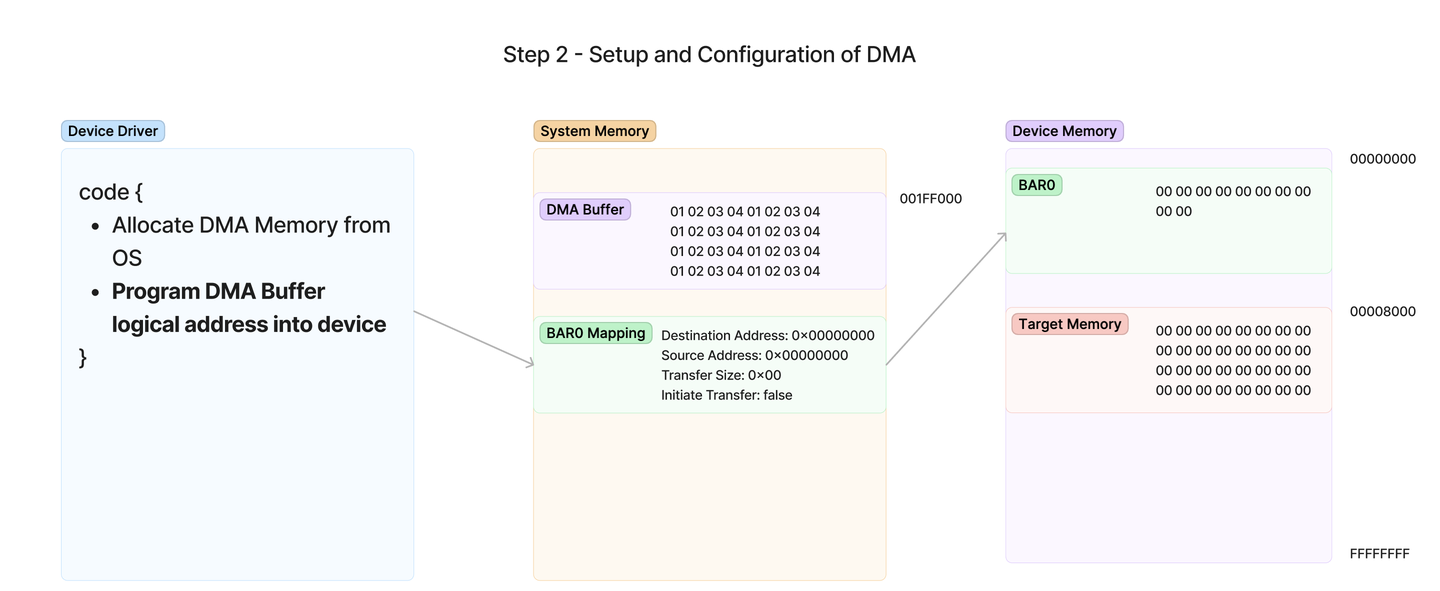
写入后数据
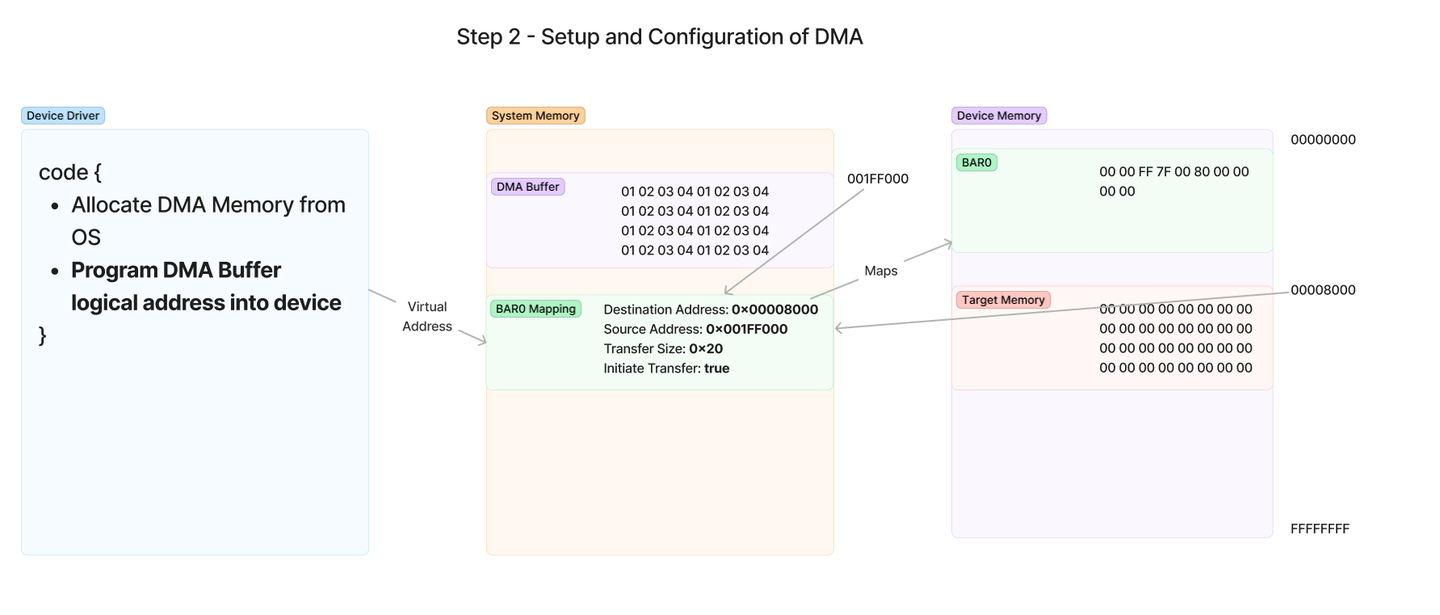
设备执行 DMA 事务
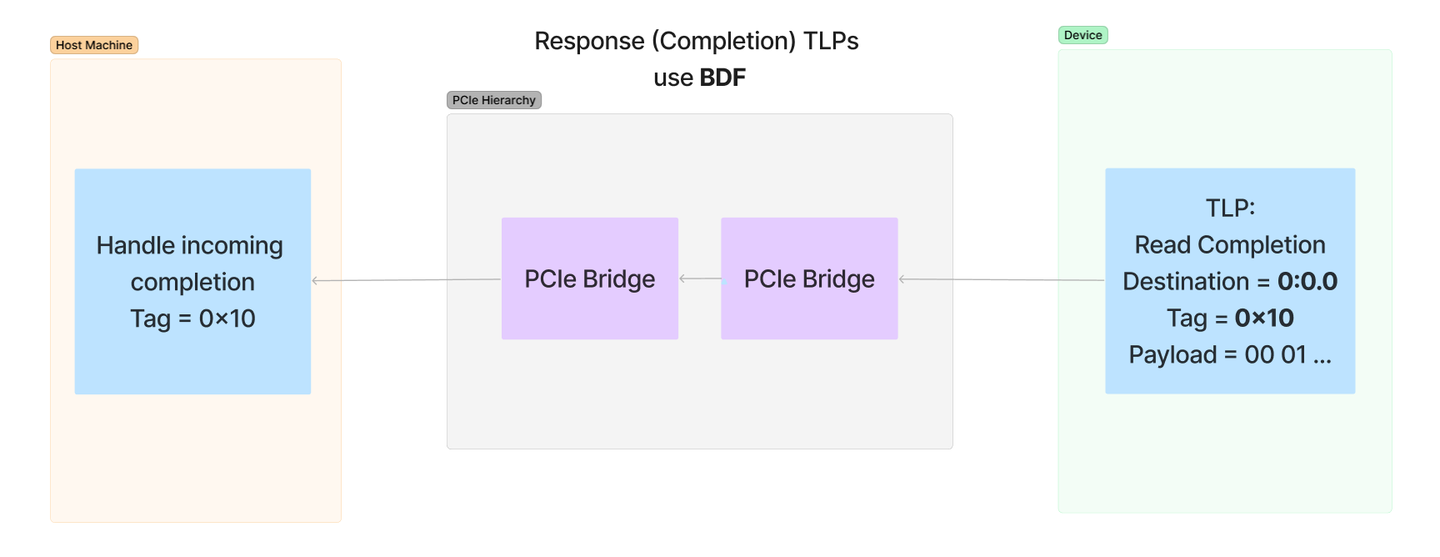
下面是内存读取和响应的图表,展示了请求使用地址发出请求,而完成使用请求的请求者字段中的 BDF 发送响应:
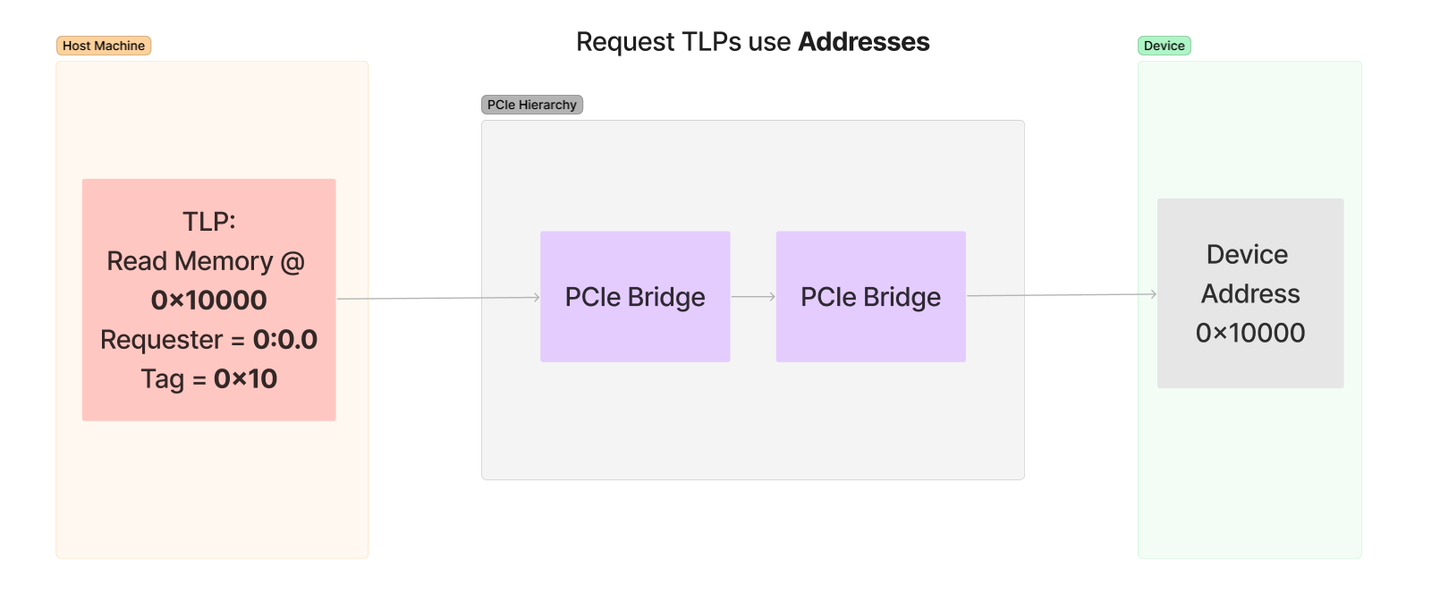
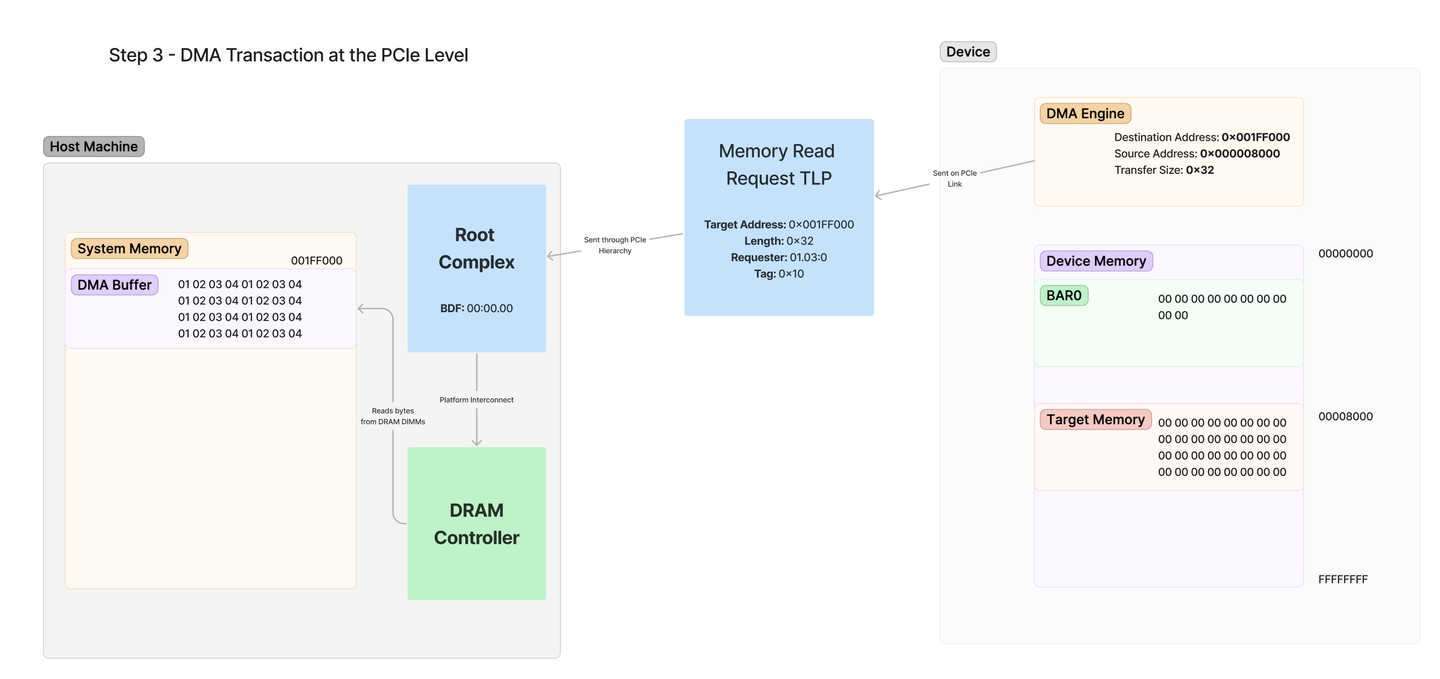
该图中概述的步骤如下:
DMA 引擎创建 TLP—— DMA 引擎识别到它必须从 0x001FF000 读取 32 个字节。它生成包含此请求的 TLP,并通过其本地 PCIe 链路将其发送出去。TLP 遍历层次结构—— PCIe 的交换层次结构将此请求通过桥接设备移动,直到到达目的地,即根联合体。回想一下,RC 负责处理所有旨在访问系统 RAM 的传入数据包。DRAM 控制器已通知—— 根联合体内部与负责实际访问系统 DRAM 内存的 DRAM 控制器进行通信。从 DRAM 读取内存—— 从地址 0x001FF000 处的 DRAM 请求给定长度的 32 字节,并将其返回到根联合体,值为 01 02 03 04…
最后,完成信息从根联合体发送回设备。注意,目的地与请求者相同:
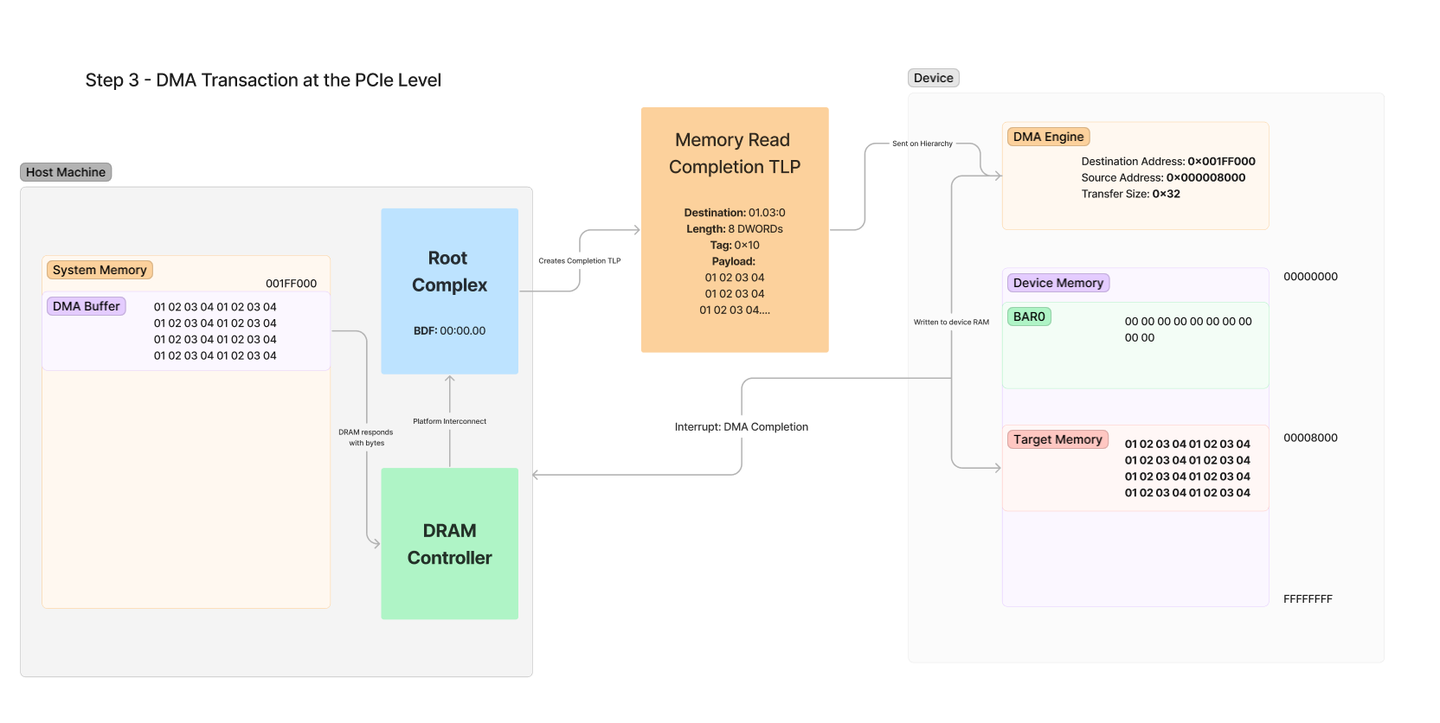
以下是上面响应包中概述的步骤:
内存从 DRAM 读取—— DRAM 控制器从系统 DRAM 中 0x001FF000 处的 DMA 缓冲区地址读取 32 个字节。DRAM 控制器响应根联合体—— DRAM 控制器内部将从 DRAM 请求的内存响应到根联合体根复合体生成完成—— 根复合体跟踪传输并为从 DRAM 读取的值创建完成 TLP。在此 TLP 中,元数据值是根据 RC 拥有的待处理传输的知识设置的,例如发送的字节数、传输的标签以及从原始请求中的请求者字段复制的目标 BDF。DMA 引擎接收 TLP—— DMA 引擎通过 PCIe 链路接收 TLP,并发现标签与原始请求的标签相同。它还会在内部跟踪此值,并知道有效载荷中的内存应写入目标内存,该内存位于设备内部 RAM 中的 0x8000 处。目标内存已写入—— 设备内存中的值将使用从数据包有效负载中复制出来的值进行更新。系统中断—— 虽然这是可选的,但大多数 DMA 引擎将配置为在 DMA 完成时中断主机 CPU。当设备成功完成 DMA 时,这会向设备驱动程序发出通知。
再次强调,处理单个完成数据包涉及很多步骤。但是,您可以再次将整个过程视为“从设备请求中收到 32 个字节的响应”。其余步骤只是为了向您展示此响应处理的完整端到端流程。
五、USB Root Hub DMA 传输
usb 首先要准备数据,其大致流程如下:

函数 map_urb_for_dma 会根据 Hub 类型调用不同的函数来分配 DMA 内存空间。
// drivers/usb/core/hcd.c
static int map_urb_for_dma(struct usb_hcd *hcd, struct urb *urb,gfp_t mem_flags)
{if (hcd->driver->map_urb_for_dma)return hcd->driver->map_urb_for_dma(hcd, urb, mem_flags);elsereturn usb_hcd_map_urb_for_dma(hcd, urb, mem_flags);
}
hcd->driver->map_urb_for_dma 实现了 usb root hub 的差异化,其可以根据自己的能力调用不同的函数来实现分配 DMA 的差异化。
在 Linux 内核中,usb_hcd_map_urb_for_dma 是 USB 主机控制器驱动(HCD)中与 DMA(直接内存访问) 关键操作相关的函数,其核心功能是为 USB 请求块(URB)配置 DMA 传输所需的硬件资源。以下从功能、实现逻辑和应用场景三个维度进行详细分析:
1. usb_hcd_map_urb_for_dma
usb_hcd_map_urb_for_dma 是 Linux 内核 USB 子系统中 USB 主机控制器驱动(HCD) 的核心函数,负责为 USB 请求块(URB)建立 DMA 映射,确保主机控制器能直接访问内存数据。以下结合代码逐层分析其功能与实现逻辑:
// drivers/usb/core/hcd.c
int usb_hcd_map_urb_for_dma(struct usb_hcd *hcd, struct urb *urb,gfp_t mem_flags)
{enum dma_data_direction dir;int ret = 0;/* Map the URB's buffers for DMA access.* Lower level HCD code should use *_dma exclusively,* unless it uses pio or talks to another transport,* or uses the provided scatter gather list for bulk.*/if (usb_endpoint_xfer_control(&urb->ep->desc)) {if (hcd->self.uses_pio_for_control)return ret;if (hcd->localmem_pool) {ret = hcd_alloc_coherent(urb->dev->bus, mem_flags,&urb->setup_dma,(void **)&urb->setup_packet,sizeof(struct usb_ctrlrequest),DMA_TO_DEVICE);if (ret)return ret;urb->transfer_flags |= URB_SETUP_MAP_LOCAL;} else if (hcd_uses_dma(hcd)) {if (object_is_on_stack(urb->setup_packet)) {WARN_ONCE(1, "setup packet is on stack\n");return -EAGAIN;}urb->setup_dma = dma_map_single(hcd->self.sysdev,urb->setup_packet,sizeof(struct usb_ctrlrequest),DMA_TO_DEVICE);if (dma_mapping_error(hcd->self.sysdev,urb->setup_dma))return -EAGAIN;urb->transfer_flags |= URB_SETUP_MAP_SINGLE;}}dir = usb_urb_dir_in(urb) ? DMA_FROM_DEVICE : DMA_TO_DEVICE;if (urb->transfer_buffer_length != 0&& !(urb->transfer_flags & URB_NO_TRANSFER_DMA_MAP)) {if (hcd->localmem_pool) {ret = hcd_alloc_coherent(urb->dev->bus, mem_flags,&urb->transfer_dma,&urb->transfer_buffer,urb->transfer_buffer_length,dir);if (ret == 0)urb->transfer_flags |= URB_MAP_LOCAL;} else if (hcd_uses_dma(hcd)) {if (urb->num_sgs) {int n;/* We don't support sg for isoc transfers ! */if (usb_endpoint_xfer_isoc(&urb->ep->desc)) {WARN_ON(1);return -EINVAL;}n = dma_map_sg(hcd->self.sysdev,urb->sg,urb->num_sgs,dir);if (!n)ret = -EAGAIN;elseurb->transfer_flags |= URB_DMA_MAP_SG;urb->num_mapped_sgs = n;if (n != urb->num_sgs)urb->transfer_flags |=URB_DMA_SG_COMBINED;} else if (urb->sg) {struct scatterlist *sg = urb->sg;urb->transfer_dma = dma_map_page(hcd->self.sysdev,sg_page(sg),sg->offset,urb->transfer_buffer_length,dir);if (dma_mapping_error(hcd->self.sysdev,urb->transfer_dma))ret = -EAGAIN;elseurb->transfer_flags |= URB_DMA_MAP_PAGE;} else if (object_is_on_stack(urb->transfer_buffer)) {WARN_ONCE(1, "transfer buffer is on stack\n");ret = -EAGAIN;} else {urb->transfer_dma = dma_map_single(hcd->self.sysdev,urb->transfer_buffer,urb->transfer_buffer_length,dir);if (dma_mapping_error(hcd->self.sysdev,urb->transfer_dma))ret = -EAGAIN;elseurb->transfer_flags |= URB_DMA_MAP_SINGLE;}}if (ret && (urb->transfer_flags & (URB_SETUP_MAP_SINGLE |URB_SETUP_MAP_LOCAL)))usb_hcd_unmap_urb_for_dma(hcd, urb);}return ret;
}
(1)、函数功能概述
-
核心目标
- 为 URB 的 控制包(Setup Packet) 和 数据缓冲区(Transfer Buffer) 分配 DMA 映射。
- 根据硬件限制(如本地内存池或系统 DMA 支持)选择映射方式。
-
关键场景
- 控制传输:映射 Setup 包(仅控制端点需要)。
- 数据传输:处理批量(Bulk)、中断(Interrupt)或等时(Isoc)传输的数据缓冲区。
- 分散/聚集(Scatter-Gather):支持非连续内存的合并传输。
(2)、代码逻辑详解
1. 控制传输处理
if (usb_endpoint_xfer_control(&urb->ep->desc)) {if (hcd->self.uses_pio_for_control)return ret;if (hcd->localmem_pool) {// 使用本地内存池分配一致性内存ret = hcd_alloc_coherent(...);if (ret)return ret;urb->transfer_flags |= URB_SETUP_MAP_LOCAL;} else if (hcd_uses_dma(hcd)) {// 检查 Setup 包是否在栈上(禁止 DMA 映射)if (object_is_on_stack(urb->setup_packet)) {WARN_ONCE(1, "setup packet is on stack\n");return -EAGAIN;}// 单页 DMA 映射urb->setup_dma = dma_map_single(...);if (dma_mapping_error(...))return -EAGAIN;urb->transfer_flags |= URB_SETUP_MAP_SINGLE;}
}
- 关键点:
- PIO 模式:若 HCD 明确使用 PIO(无 DMA),直接跳过。
- 本地内存池:通过
hcd_alloc_coherent分配物理连续内存,适用于 SRAM 等受限场景。 - 系统 DMA:使用
dma_map_single映射用户空间或内核态内存,需确保内存物理连续。
2. 数据传输处理
dir = usb_urb_dir_in(urb) ? DMA_FROM_DEVICE : DMA_TO_DEVICE;
if (urb->transfer_buffer_length != 0&& !(urb->transfer_flags & URB_NO_TRANSFER_DMA_MAP)) {if (hcd->localmem_pool) {// 本地内存池分配(一致性 DMA)ret = hcd_alloc_coherent(...);if (ret == 0)urb->transfer_flags |= URB_MAP_LOCAL;} else if (hcd_uses_dma(hcd)) {if (urb->num_sgs) {// 分散/聚集映射(多页合并)n = dma_map_sg(...);if (!n)ret = -EAGAIN;elseurb->transfer_flags |= URB_DMA_MAP_SG;} else if (urb->sg) {// 单页 DMA 映射(偏移量处理)urb->transfer_dma = dma_map_page(...);} else if (object_is_on_stack(urb->transfer_buffer)) {WARN_ONCE(1, "transfer buffer is on stack\n");ret = -EAGAIN;} else {// 常规单页映射urb->transfer_dma = dma_map_single(...);}}
}
- 关键点:
- 传输方向:通过
usb_urb_dir_in确定 DMA 方向(输入/输出)。 - 分散/聚集支持:通过
dma_map_sg合并多个非连续内存页,需 HCD 支持且非等时传输。 - 栈内存检查:禁止 DMA 映射栈内存(可能导致物理地址不连续)。
- 传输方向:通过
3. 错误处理与资源释放
if (ret && (urb->transfer_flags & (URB_SETUP_MAP_SINGLE | URB_SETUP_MAP_LOCAL)))usb_hcd_unmap_urb_for_dma(hcd, urb);
- 回滚机制:若数据缓冲区映射失败但已分配 Setup 包映射,需释放 Setup 包资源。
(3)、核心设计思想
-
硬件兼容性
- 本地内存池:针对 DMA 地址受限的控制器(如仅支持小容量 SRAM),通过
hcd_alloc_coherent分配一致性内存。 - 系统 DMA:通用场景下使用
dma_map_*接口,依赖 CPU 缓存一致性协议。
- 本地内存池:针对 DMA 地址受限的控制器(如仅支持小容量 SRAM),通过
-
性能优化
- 分散/聚集合并:通过
URB_DMA_MAP_SG_COMBINED标志减少 DMA 事务次数。 - 零拷贝:直接传递用户空间缓冲区(需确保物理连续性)。
- 分散/聚集合并:通过
-
安全性保障
- 栈内存检查:防止 DMA 访问无效的栈内存地址。
- 错误回滚:映射失败时释放已分配资源,避免内存泄漏。
(4)、关键数据结构与标志
| 结构体/标志 | 作用 |
|---|---|
URB_SETUP_MAP_LOCAL | 标记 Setup 包使用本地内存池分配 |
URB_DMA_MAP_SG | 表示数据缓冲区使用分散/聚集映射 |
URB_DMA_MAP_SINGLE | 表示数据缓冲区使用单页 DMA 映射 |
hcd->localmem_pool | 指向本地内存池(如 SRAM),用于受限 DMA 场景 |
(5)、典型调用场景
-
批量数据传输
// 分配 4KB 连续内存并映射 urb->transfer_buffer = kmalloc(4096, GFP_KERNEL); ret = usb_hcd_map_urb_for_dma(hcd, urb, GFP_KERNEL); -
分散/聚集传输
// 初始化 scatterlist struct scatterlist sg[2]; sg_init_table(sg, 2); sg[0].page_link = (unsigned long)page1 + offset1; sg[0].offset = 0; sg[0].length = len1; sg[1].page_link = (unsigned long)page2 + offset2; sg[1].offset = 0; sg[1].length = len2; urb->sg = sg; urb->num_sgs = 2; ret = usb_hcd_map_urb_for_dma(hcd, urb, GFP_KERNEL);
(6)与 URB 生命周期的关系
| 阶段 | 操作 | 相关函数 |
|---|---|---|
| URB 提交前 | 分配 DMA 缓冲区并映射 | usb_alloc_urb + map_urb_for_dma |
| DMA 传输中 | 主机控制器执行数据传输 | HCD 驱动代码(如 ehci_urb_enqueue) |
| 传输完成/取消 | 解除 DMA 映射并释放资源 | unmap_urb_for_dma + usb_free_urb |
(7)总结
usb_hcd_map_urb_for_dma 是 USB 子系统中连接 CPU 内存与 DMA 控制器的桥梁,其设计需兼顾 硬件兼容性 和 性能效率。理解其实现细节对开发高性能 USB 驱动(如定制 HCD 或优化现有控制器)至关重要。
2、hcd_alloc_coherent
在 Linux 6.12.5 内核中,hcd_alloc_coherent 是 USB 主机控制器驱动(HCD)框架中用于 分配一致性 DMA 内存 的核心函数。其设计目标是确保 CPU 和 DMA 控制器对同一块内存的访问保持一致性,避免因缓存不同步导致的数据错误。以下从功能、实现细节和应用场景三个维度进行深入分析:
(1)、函数功能与设计目标
1. 核心功能
- 一致性内存分配:分配物理连续的内存区域,并建立 CPU 虚拟地址与总线地址(DMA 地址)的映射。
- 缓存一致性保障:通过页表标记或显式同步操作,确保 CPU 与 DMA 设备对内存的读写顺序一致。
2. 设计目标
- 硬件兼容性:适配不同总线类型(如 PCIe、USB)的 DMA 地址映射规则。
- 性能优化:减少 CPU 缓存刷新开销,适用于高频 DMA 传输场景(如 USB 批量传输)。
- 资源管理:与 HCD 驱动的内存池(如本地内存池
localmem_pool)集成,避免内存碎片。
☆