【机器学习】机器学习工程实战-第4章 特征工程
上一章:第3章 数据收集和准备
文章目录
- 4.1 为什么要进行特征工程
- 4.2 如何进行特征工程
- 4.2.1 文本的特征工程
- 4.2.2 为什么词袋有用
- 4.2.3 将分类特征转换为数字
- 4.2.4 特征哈希
- 4.2.5 主题建模
- 4.2.6 时间序列的特征
- 4.2.7 发挥你的创造力
- 4.3 叠加特征
特征工程是将原始样本转化为特征向量的过程。
4.1 为什么要进行特征工程
比如,机器学习算法只能应用于特征向量,不能直接识别文本,所以需要借助特征工程。
4.2 如何进行特征工程
4.2.1 文本的特征工程
常使用的两种方法:
独热编码(one-hot encoding):将一个分类属性转化为多个二进制属性。
比如,数据集中的“颜色”属性,可能的值有红、黄、绿。我们将属性值转化为一个三维二进制向量:
红=[1,0,0]
黄=[0,1,0]
绿=[0,0,1]
然后使用这三个合成列来代替原来的“颜色”列属性。词袋(bag-of-words):是将独热编码技术应用与文本数据的一种泛化。区别与将一个属性表示为二进制向量,词袋是将整个文本文档表示为二进制向量。
首先,将文本词条化。
词条化(tokenization)是将文本分割成小块的过程,这些小块称为“词条”。
词条器(tokenizer)是将字符串输入转化为返回该字符串中一系列词条的软件工具。
通常情况下,词条是单词,也可以是一个标点符号、单词的组合等。
其次,建立一个词汇表,包含文本词条化后的所有单词。对词汇表进行排序后,为每个词条分配一个索引。
将文本集合转化为二元特征向量的集合:若文本中存在相应的词条,改位置特征记为1,否则记为0。
通常有以下几种形式的词袋:
①词条的计数
②词条的频率
③TF-IDF(Term Frequency-Inverse Document Frequency,术语频率-反转文档频率)
词袋技术的直接扩展是n元连续词袋(bag-of-n-gram)。
n元连续词(n-gram)是从语料库中抽取的n个单词的序列。如果n=2,并且忽略标点符号,则文本“No,I am your father.”中可以找到的所有二元连续词(通常称为bigrams)包括[“No I”“I am”“am your”“your father”]。三元联系次是[“No I am”“I am your”“am your father”]。通过将一定n以内的所有n元连续词与一个词典中的词条混合,得到一个n元连续词袋,我们可以用处理词袋模型的方式来词条化。
因为词的序列通常比单个词的常见度低,所以使用n元连续词可以创建更 稀疏(sparse)的特征向量。同时,n元连续词允许机器学习算法学习更细微的模型。如,“this movie was not good and boring”和“this movie was good and not boring”的意思是相反的,但仅仅基于单词,就会得到相同的词袋向量。如果使用二元连续词,那么这两个句子的二元连续词的词袋向量就会不同。
4.2.2 为什么词袋有用
词袋技术的工作原理与特征向量是一样的。即每个特征都代表文档的同一属性:特定的词条在文档中是存在还是不存在。
相似的特征向量必须代表数据集中的相似实体。两个相同的文档应当具有相同的特征向量。同样,关于同一主题的两个文本将有更高的机会拥有相似的特征向量,因为他们会比两个不同主题的文本共享更多的单词。
4.2.3 将分类特征转换为数字
- 独热编码
- 均值编码(mean encoding),也称为箱计数(bin counting)或特征校准(feature calibration)
首先,使用具有特征值z的所有样本来计算标签的样本均值(sample mean),然后用这个样本均值替换该分类特征的每个值z。这种技术的优点是数据维度不会增加,但数值包含了标签的一些信息。 - 让步比(odd ratio)和对数让步比(log-odd ratio)
在二分类问题中,除了样本均值外,也可以使用其他有用的量。
让步比(OR)通常定义在两个随机变量之间。 从一般意义上讲,OR是量化两个事件A和B之间关联强度的统计量,如果两个事件的OR等于1,即一个事件在另一个事件存在或不存在的情况下,其概率都相同,则认为两个事件是独立的。 - 正弦-余弦变换(sine-cosine transformation)
如果分类特征是周期性的,请使用正弦-余弦变换。它将周期性特征转换为两个合成特征。
令p表示我们周期性特征的整数值,将周期性特征值p替换为以下两个值:
p s i n = s i n ( 2 × π × p m a x ( p ) ) p_{sin} =sin(\frac{2×π×p}{max(p)}) psin=sin(max(p)2×π×p)
p c o s = c o s ( 2 × π × p m a x ( p ) ) p_{cos} =cos(\frac{2×π×p}{max(p)}) pcos=cos(max(p)2×π×p)
下图为一周七天的 p s i n p_{sin} psin和 p c o s p_{cos} pcos值:
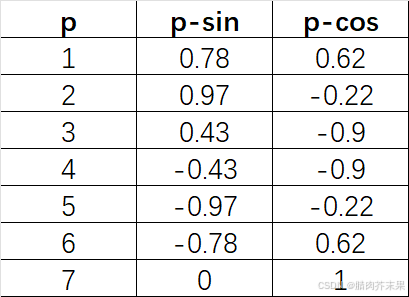
两个值[0.78,0.62]替换“周一”,以此类推。
数据集增加了一个维度,但与整数编码相比,模型的预测质量明显提高。
绘制的散点图如下:

4.2.4 特征哈希
特征哈希(feature hashing)或哈希技巧(hashing trick),将文本数据或具有许多值的分类属性转换为任意维度的特征向量,
独热编码和词袋编码有一个缺点:许多独特的值将创建高维的特征向量。处理这样的高维数据,计算成本非常昂贵。
为了使数据易于管理,可以使用哈希技巧。
首先,决定特征向量所需的维度,然后使用哈希函数(hash function)将分类属性(或文档集合中的所有词条)的所有值转换为特定数字,然后将这些数字转换为特征向量的索引。
举例:将文本“Love is a doing word”转换为特征向量。
设我们有一个哈希函数h,它接受一个字符串作为输入,输入一个非负整数,并设所需的维度为5。将哈希函数应用于每个词,并应用5的模数来获得该词的索引。可以得到:
h(love) mod 5 = 0
h(is) mod 5 = 3
h(a) mod 5 = 1
h(doing) mod 5 = 3
h(word) mod 5 = 4
然后建立特征向量为[1,1,0,2,1]。
这个特征向量怎么来的?
首先,向量的维度为5,那么它的维度分别是维度0,维度1,维度2,维度3,维度4。
h(love) mod 5 = 0,即,维度0有一个词,那么特征向量的第一个数字就是1;
h(is) mod 5 = 3和h(doing) mod 5 = 3,即,维度3有两个词,那么特征向量的第四个数字是2;
其它的逻辑相同,就得到了特征向量[1,1,0,2,1]。
我们发现,“is”和“doing”都用维度3表示看,这两个词之间存在碰撞(collision)。所需的维度越低,碰撞的概率就越大。这是学习速度与质量之间的权衡。
常用的哈希函数有MurmurHash3、Jenkins、CityHash和MD5。
4.2.5 主题建模
主题建模是使用无标签数据的一系列技术,这些数据通常以自然语言文本文档的形式存在。
模型学习将文档表示为主题的向量。
例如,在新闻文章的集合中,5个主要主题可以是“体育”“政治”“娱乐”“金融”“技术”。然后每个文档可以被表示为一个5维的特征向量,每个主题一个维度:
[0.04,0.5,0.1,0.3,0.06]
这个特征向量代表了一个文档,它混合了两大主题:政治(权重为0.5)和金融(权重为0.3)。
主题建模算法,如潜在语义分析(Latent Semantic Analysis,LSA)和潜在狄利克雷分布(Latent Dirichlet Allocation,LDA),通过分析无标签的文档进行学习。这两种算法基于不同的数学模型产生类似的输出。
LSA使用“词到文档”矩阵的奇异值分解(Singular Value Decomposition,SVD),该矩阵使用二元连续词袋或TF-IDF构建。
LDA使用的是分层贝叶斯模型(Bayesian model),其中每个文档是几个主题的混合(mixture),每个词的出现归因于其中一个主题。
4.2.6 时间序列的特征
在经典时间序列数据(classical time-series data)中,观测值在时间上的间隔是均匀的,比如每秒、每分钟、每天等都有一次观测。
如果观测值是不规则的,这样的时间序列数据称为点过程(point process)或事件流(event stream)。
通常可以通过聚合观测结果,将事件流转换为经典时间序列数据。
在神经网络达到现在的学习能力之前,分析师使用浅层机器学习(shallow machine learning)工具箱处理时间序列数据。
为了将时间序列转化为特征向量形式的训练数据,必须做两个决定:
- 需要多少个连续的噶u你厕纸才能做出准确的预测(所谓的预测窗口);
- 如何将观测值序列转换为固定维度的特征向量。
这两个问题都没有简单的方法来回答。通常是根据主题专家的知识,或者通过使用超参数调整(hyperparameter tuning)计算来做出决定。
以下的方法对许多时间序列数据都有效:
(1)把整个时间序列分成长度为w的片段;
(2)从每个片段s中创建一个训练样本e;
(3)对于每个e,计算s中观测值的各种统计量。
假设预测窗口的长度为7,步骤(3)中的统计数据可以是: - 平均数,例如过去7天内股价的均值(mean)或中位数(median)。
- 价差,例如,标准普尔500指数在过去7天内的标准差(standard deviation)、绝对偏差中位数(median absolute deviation)或四分位数范围(interquartile range)。
- 离群值,例如,道琼斯指数的数值非典型偏低的观测值的部分,与均值相差两个标准差以上。
- 增长,例如,标准普尔500指数的数值在t-6日和t日之间、t-3日和t日之间、t-1日和t日之间是否有增长。
- 视觉,例如,股票价格的曲线与已知的视觉形象(如帽子形态、头肩顶形态等)有多大差异。
将时间序列转换为经典形式的作用:上述统计量只有在可比值上计算时才有意义。
在现代神经网络时代,分析师最喜欢训练深度神经网络。
长短期记忆(Long Short-Term Memory,LSTM)、卷积神经网络(Convolutional Neural Network,CNN)和Transformer是时间序列模型架构的流行选择。
4.2.7 发挥你的创造力
特征工程是一个创造性的过程,由分析师决定哪些特征最适合自己的预测模型。
4.3 叠加特征
后续待更新
发现这本书的翻译不是特别好,多是字面直译过来,甚至有的地方不够通顺。我还需要将中文翻译成中文。。 要求翻译者精通机器学习显然不现实,加上这本书基本都是理论内容,所以后续考虑粗读一些。
以后我会尽量选择清北等出版社的图书,质量应该会更高。
请在关闭网页之前,利用2秒钟的时间,在脑海中迅速回顾一遍本部分的框架及要点!