精华帖分享 | 从华泰研报出发,开启人工智能炼丹篇章!
本文来源于量化小论坛策略分享会板块精华帖,作者为1go的程序猿,发布于2024年3月30日。
以下为精华帖正文:
最近研究完邢大新发布的各种框架后,突然冒出了想当牛马的想法。但是,本人作为一个量化小白,从头开始到变成牛马那必定是道阻且长。于是我决定从彩虹几乎没有涉及到的角度入手:做人工智能深度学习系列。
那为什么要做这个系列呢?人工智能的原理究竟是什么?能带给我们什么?
随着AI大模型的爆火,人工智能进入了大家的视野。现在的人工智能模型大致包含如下几种:语言模型、图像视频模型、音频模型、时间序列模型等等。
人工智能在图片文本领域的能力大家有目共睹(gpt,sora....),那将其应用在量化领域会不会给大家带来超乎想象的收益呢。
我翻阅了一下彩虹论坛上关于人工智能的研究,几乎没有可以应用于实盘的,那就只能从研报中寻找思路了。
简单的读了海通、广发、华泰的几篇相关研报后,发现还是华泰的研报写的详细,思路连贯开阔。与多因子选股模型相关的主要包含两部分:因子生成与合成、对抗过拟合。
几篇研报中的模型效果都还不错,而且不难实现。正巧,最近在学校研究时间序列模型,那直接准备一波爆肝,把邢大的选股框架和人工智能一结合,新款的丹炉说不定就出来了!
但是问题来了,理想很丰满,现实很打脸。前几天发过一篇微软AI炒股的论文解读,阅读量那是相当低。。。仔细一想,大部分人都没接触过人工智能模型,那再看原理公式啥的就更看不懂了。
那想让大家接受人工智能模型,还是得从头说起,这个听起来很高大上的东西到底工作原理是什么?
01
深度学习简介
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。
上面的解释来源于百度百科,就很复杂,我把它精简一下:深度学习就干俩事,从已知数据中提取信息、并合成出“未知”的信息。
02
提取信息
深度学习,到底从哪学,学什么?在量化领域,深度学习主要的学习对象包含股票基本数据,另类数据等。
基本数据即全市场所有股票最近几年的开高收低量价以及基本面等数据;另类数据包含文本数据即市场舆论、新闻、分析师研报等、基金经理持仓等大家不常用的数据。
深度学习模型在得到这些数据后第一步就是进行信息提取,即模型的编码器部分。
编码:字面意思,将输入的数据编成码。例如摩斯密码就是一种编码方法,将26个字母变成更复杂的特征。
深度学习模型也是类似,可以从输入的数据中学习更多特征信息,并将其转换为高维度多特征的向量输出。直接说有点抽象哈,高维度、多特征是啥东西?
维度:举个例子,原始的股票数据包含三个维度:时间维度(如2020年-2023年所有交易日),股票特征维度(单只个股的开高收低、各种因子值),股票池维度(全市场所有股票)。
特征:我对特征的理解就是在单一维度上,这个向量到底有多长。例如某股票在某天的开.高.收.低价格就是4个特征。一周五个交易日就是五个特征。
这些已知特征在模型挖掘后可以生成更多的特征,挖掘出未知的特征值:例如我输入了近20天的个股收盘价数据,模型就可以推算出20日均线这一特征的值,信息便从长为4的向量(开高收低)变成了长度为5的向量(多加了均线)。
听起来也一般般哈,均价我们手动不是也能算嘛。但是深度学习模型厉害的点在于可以通过权重组合、添加非线性等手段获得我们无法计算的特征。
03
合成结果
那挖掘出特征后,模型还可以将信息合成出我们想要的结果,这便是模型的解码器部分。还是拿摩斯密码举例,我们拿到了摩斯密码表示的文章后我们也看不懂啊,那就得反向操作一下,通过密码本将其转换为字母。
深度学习模型现在可以做的合成任务例如,回归——计算某天股价具体涨跌,二分类——计算某天某支股是涨还是跌,多分类——文字的生成,具体输出26个字母中的哪个。
至于从什么数据中提取信息,怎么提取信息,合成什么样的结果,是个很大的坑,要以后慢慢来填了。先看看人工智能它能带给我们什么,提取合成的信息到底好不好用。
04
华泰做了什么?
华泰去年发表了一篇研报《华泰人工智能研究6周年回顾》。华泰用人工智能就做了三件事 1.模型测试 2.因子挖掘 3.对抗过拟合。
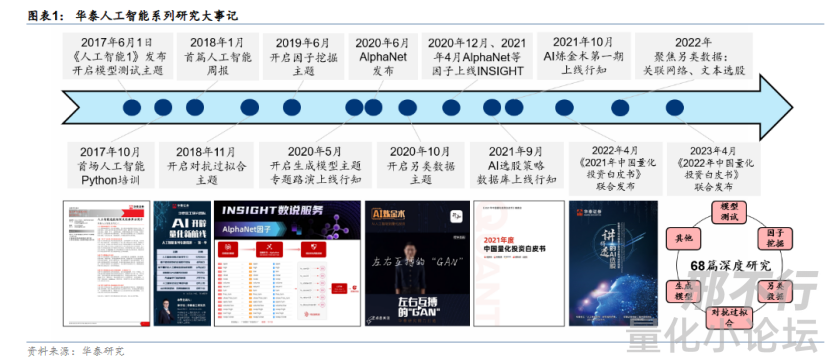
2017年-2020年研究了模型测试,使用了传统机器学习(我不咋会...),这里跳过哈。
2019年6月,华泰开始做因子挖掘。从开始的传统机器学习模型到2020年6月的AlphaNet模型,华泰人工智能系列开始向深度学习转型。华泰研究的模型很多,AlphaNet、GRU、GNN啥的,但核心没变,主要研究的都是基础数据,如量价数据等,并从中挖掘信息,生成了单因子、多因子。
2020年开始,华泰开始拓宽思路,进行了另类数据研究。大家最熟悉的应该是文本数据,最近gpt的爆火,让大家也体验到了,人工智能模型可以做到分析文本情感,挖掘语义等,借助语言模型,华泰构建了基于舆情、基于研报情感等选股策略。


过拟合也是量化中令人头大的一件事,人工智能模型也能帮我们解决这一问题。从2019年末,华泰开始对GAN(生成对抗网络)进行很多研究。
GAN能gan什么呢:它可以生成假数据!以前我们都是在历史数据上进行回测,找最优参数。那历史容易过拟合,我们就创造一些没发生过的历史,这样不就从根源上解决了过拟合嘛。

说了这么多,想让大部分老板接受,那还是得向彩虹学习,老板们只需要配config就行了,什么模型实现,数据、因子挖掘交给卷王就好了。再狠狠表扬一下彩虹集团,新的选股框架很牛逼哈!里面能复用的部分非常多,把人工智能模型塞进去也不费劲。之后向这个方向努力一下,发出来的代码大家配config就行。
05
篇末预告
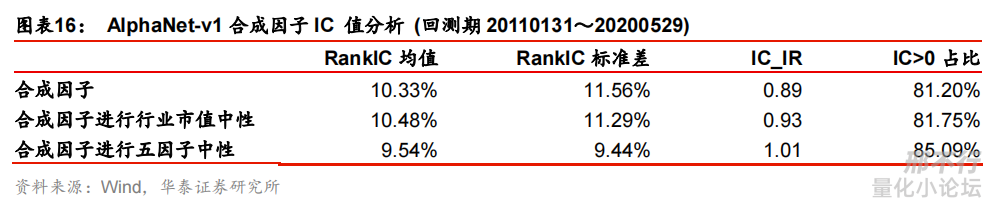
其实已经复现了华泰的AlphaNet,研报里的实验结果相当不错(但毕竟是华泰第一个深度学习模型,现在直接拿来用的效果我不太看好)。
下图是《20200614-华泰人工智能系列之三十二:AlphaNet:因子挖掘神经网络-华泰证券》中挖掘出的单因子ICIR分析,效果远超大部分传统因子。正在尝试着塞到选股框架里,自己测试一下。如果测试效果还不错的话,下一篇就给大家透一下。