JVM详解
目录
一,JVM内存区域划分
1,程序计数器
2,堆
3,栈
4,元数据区
二,JVM类加载过程
第一步:加载
双亲委派模型的工作流程:
第二步:验证
第三步:准备
第四步:解析
第五步:初始化
三,JVM垃圾回收机制
1,找出垃圾
方案一:引用计数法:
方案二:可达性分析
2,释放空间
方案一:标记清除法
方案二:复制算法
方案三:标记整理法
方案四:分代回收
本篇文章,我们讨论三个问题1,JVM内存区域划分2,JVM类加载过程3,JVM垃圾回收机制
一,JVM内存区域划分
一个Java进程(资源分配的基本单位)就是JVM加上上面运行的字节码指令
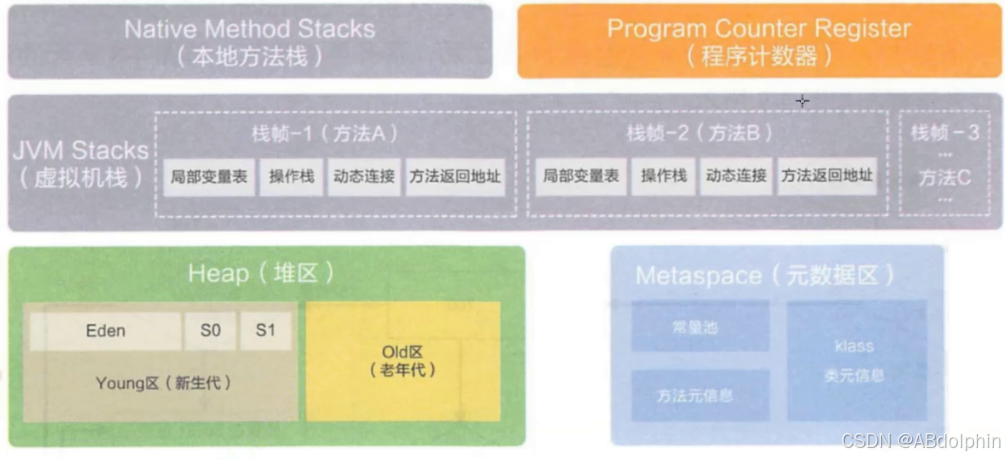
1,程序计数器
程序计数器是一个较小的空间,他保存了下一条指令的地址(这个地址指向元数据区),这里的指令是Java字节码,而非CPU上的二进制机械语言
2,堆
堆,JVM上最大的空间,new出的对象都在堆上.
3,栈
栈函数中的局部变量,函数的形参,函数之间的调用关系.栈分为两类,分别为Java虚拟机栈,和本地方法栈.
Java虚拟机栈:JVM之上,运行的Java代码方法的调用关系
本地方法栈:JVM里面,出++代码函数调用关系
4,元数据区
元数据区(原称"方法区"),保存代码中类的相关信息,Java中的指令,指令都是包含在类的方法中的,类的static属性也包含于此
在一个Java进程中.堆和元数据区,只有一份,程序计数器和栈有多份(多线程时)
变量的类型:局部变量:栈;成员变量:堆;静态变量:元数据区
方法执行完毕后就会被销毁,如果要调用新的方法,就会创建新的栈帧
二,JVM类加载过程
一个Java程序 .Java文件 =编译[javac]=>.class文件,JVM类加载的过程就是JVM读.class指令的过程.使文件加载到内存中,把.class文件变成一个类对象(包含.class各种信息),基于类对象就可以创建类的实例.各种反射的API就是从类对象中取得值.
类加载输入:.class(类的全限定名)
类加载得到的结果:内存中对应的类对象
类对象的加载步骤(五步):
第一步:加载
把.class文件找到,在代码中先找到类的名字,然后进一步找到对应的.class文件(涉及到一系列目录查找的过程),打开读取文件内容
遵循"双亲委派模型":(给定类全限定名->找到对应的.class文件的位置)JVM中内置了类加载器,完成上述类加载的过程,JVM默认有三个类加载器:
<爷>BootstrapClassLoader 负责加载标准库的类,标准库有一个专门存放的位置,就会在那个位置进行查找相关的类
<父>ExtensionClassLoader负责加载扩展类(由JVM厂商提供,希望对Java的功能进行进一步的扩展)
<子>ApplicationClassLoader 负责加载第三方库/自己写的类
他们的关系并不是继承的关系,而是子类加载器中有一个指向parent引用,指向父类
双亲委派模型的工作流程:
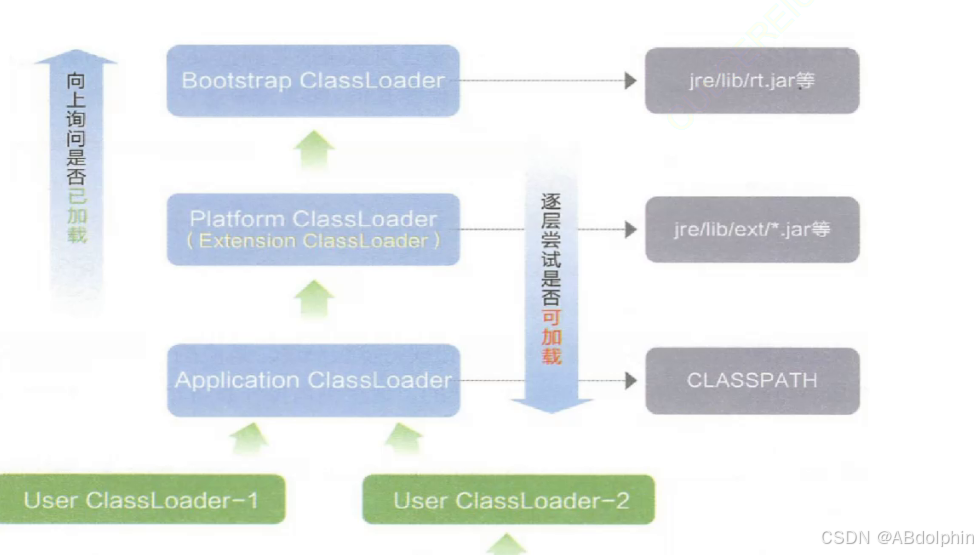
输入:类的全限定名,类似于Java.long.String=>得到:对应的.class文件
最开始从ApplicationClassLoader进行加载,但是并不扫描目录,而是要询问ExtensionClassLoader,也不会立刻扫描目录,而是要询问BootstrapClassLoader,也不会立刻扫描目录,也要向上询问,父亲为空,所以进行扫描,如果找到了,就进行(2,3,4,5步),如果没找到就将任务传给孩子(ExtensionClassLoader)进行扫描,如果找到,就进行(2,3,4,5步),如果没找到就将任务传给孩子(ApplicationClassLoader),进行扫描,如果找到,就进行(2,3,4,5步),如果没找到,才是就会触发ClassNotFoundException异常,抛出异常.
设计原因:
这样设计的核心目的就是,防止用户自己写的类将标准库中的类覆盖掉,保证标准库中的类被加载的优先级是最高的,扩展库其次,第三方库优先级最低,若程序员不小心将类名重复了,按照上述规则,就可以保证最多用户自己的类用不了,不会造成其他负面影响(代码的大规模破坏)
第二步:验证
验证.class文件是否合法(Java标准文档中明确规定了.class格式是怎样的)

前者是Java的语法规范,后者是JVM规范

(其中:u2代表两个字节的无符号整数 unsigned short.u4代表四个无符号整数unsigned int)
magic:魔幻数字,二进制文件会在文件头设置若个字节,设置一个固定的常量进去,通常这个常数表示当前文件是一个怎样的文件(图片,音频....)
minor_version/major_version:版本号,确保编译和运行使用的jdk版本一致(高版本可以运行低版本的编译结果,但尽量保持两者一致)
constant_pool_count/constant_pool[constant_pool_count]:数组长度/常量池,每一个元素都是cp_info这样的结构体
field_count/fields[field_count]:类的属性
methods_count/methods[methods_count]:类方法
attributes_count/attributes[attributes_count]:其他属性
二进制文件通常就是按照上述方式进行存储的.
第三步:准备
分配内存空间,最终需要得到类对象,根据刚刚读取到的内容计算出类对象的大小,并申请这样大小的空间,把空间所有的内容都初始化为0(通常,在Java中创建一个内存空间,就会将其初始化为0,后续再进一步初始化,这样可以避免残留数据对当前代码误使用,从而造成bug,但是c++/c不会进行置0操作,所以当前数据就是上次的残旧数据,因为全部置为0,非常影响性能)final修饰的就会直接进行初始化为设定的值
第四步:解析
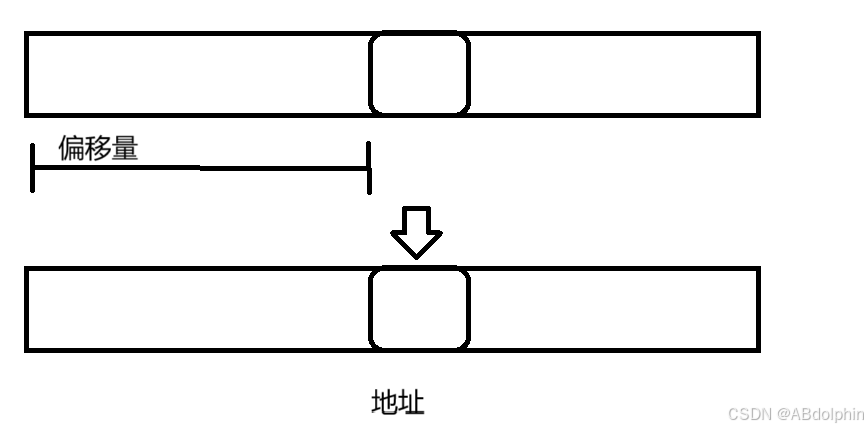
主要针对类中的字符串常量,是将Java虚拟机将常量池中的符号引用转化为直接引用的过程,也就是初始化的过程.直接引用也就是平常代码中的引用,指向的是当前变量的地址,
符号引用:在文件的时候,没有地址这样的概念,所以取而代之的是"文件偏移量"这样的说法,文件中有很多指令,比如说用到"hello"这个常量,这些指令就会使用"hello"的偏移量进行表示
第五步:初始化
针对类对象进行最终的初始化,执行静态成员变量的赋值语句,执行类中静态代码块,针对父类进行加载(如果当前类有父类,且父类没有进行加载,那么这个过程将会触发父类的加载)
三,JVM垃圾回收机制
c++对于内存泄漏,=>"智能指针"
Java对于内存的泄漏=>"垃圾回收"JVM自动识别那些new的对象再也不会用了,就把这样的对象释放掉.但是GC也是有代价的:JVM中引入了额外的逻辑消耗了CPU的开销,进行垃圾扫描和释放,而且GC的时候有可能会触发STW(stop the world)问题,导致程序卡顿.因此GC对性能要求比较高的的场合影响就会比较大
程序计数器,栈,元数据区不需要回收,堆是主战场,主要是回收对象
回收流程:
1,找出垃圾
方案一:引用计数法:
如果一个对象没有引用指向了,就可以视为垃圾了,给每个对象分配一个计数器,每增加一个引用就+1,每减少一个引用就-1,当计数器为0的时候,对象就是垃圾了.但是上述方案JVM并没有采纳,
原因:消耗额外空间(如果对象本身就小,那么计数器的就显得额外大),引用计数可能导致"循环引用"使计数器判断错误,这时就需要引入循环检测机制
方案二:可达性分析
(用时间换空间)JVM专门搞了一波线程同时期的扫描代码中的所有对象,判定某个对象是否可达,,如果不可达就会被视为垃圾.(类似于JVM有一个所有对象的总名单,单名,如果在就是可达,如果不在就会被视为垃圾)
可达分析的起点称之为"GC root"一个程序中有多个GC root.(栈上的局部变量[引用类型],方法区中静态成员[引用类型],常量池引用指向的对象).把所有的GC root都遍历一遍,向下延伸.
2,释放空间
方案一:标记清除法
直接针对内存中的对象进行清除,这样会引起"内存碎片"问题.由于内存空间没有连续到一起,所以空间申请不到.<尽可能避免有内存碎片,这时释放内存的关键问题>
方案二:复制算法
将空间一份为二,只使用其中一半,需要释放内存的时候,将不是垃圾的对象连续赋值到另外一半的空间,然后将原来的一半空间全部释放掉.
缺点:内存空间的使用率较低,而且如果存活下来的对象较多,那么复制将会有较大的成本
方案三:标记整理法
类似于顺序表中在中间删除数据的算法(搬运的成本也比较大)
方案四:分代回收
JVM的解法是综合了上述所有的方法:
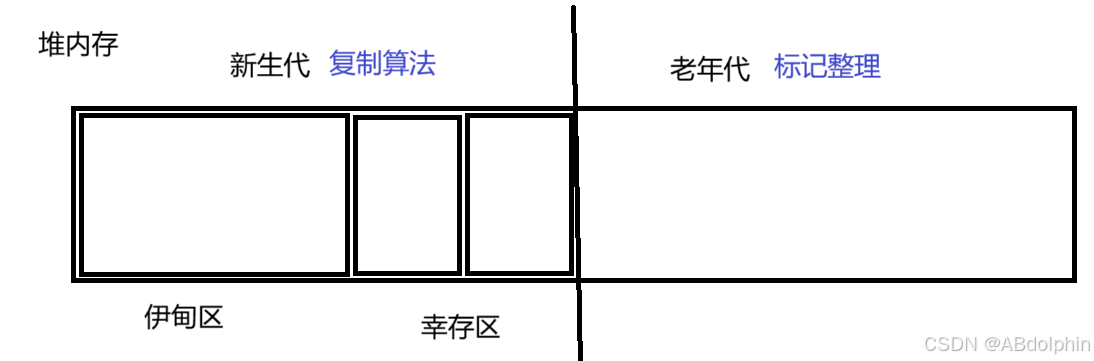
伊甸区:创建的新的对象放到伊甸区,根据经验,大多数对象活不过第一轮,留下的对象就会拷贝到幸存区
幸存区:两个相等的空间,按照复制算法,反复进行多次
老年代:如果一个在幸存区反复存活,,到达一定年纪,就会拷贝到老年区,根据经验,老年区的生命周期普遍较长,因此进行可达性周期降低
分代回收是JVM的基本思想方法,落实到JVM的实现层面,JVM提供了多种"垃圾回收器"对上述分代回收进一步的扩充和具体实现.
比较重要的是G1和GMS
G1对整个内存分成更多小块,进行GC,不要求一个周期将所有的内存都遍历一遍,而是一轮GC只回收其中一小部分,从而控制STW时间
GMS:把整个GC分成多个阶段,与业务线程并发执行,尽可能减少STW的时间