JavaSE——集合9:Map接口实现类—HashMap(重要!!!)
目录
一、HashMap概述
二、HashMap添加重复键源码解析
三、HashMap底层机制及源码剖析
(一)扩容机制(和HashSet相似)
第一次添加:
1.首先,调用构造器,初始化加载因子
2.初始化后table表为null
3.基本数据类型的装箱,转为一个对象
4.执行put方法
5.计算key的hash值
6.返回并执行putVal方法
7.初次存放数据之前,判断table表是否为空,table=null,则进行扩容
8.执行resize方法
9.返回table表的长度
10.得到索引,索引位置为null,就放进去
11.放入索引位置后,继续判断是否需要扩容
第二次添加:
1.基本数据类型进行装箱,转为一个对象
2.重新计算hash值
3.再次判断table数组是否为null
4.table数组不为null,则计算索引,索引位置没有元素,创建新的Node,添加元素
5.再次判断当前元素数量是否超过临界值
6.没有超过,返回null
第三次添加:
1.仍旧进行装箱操作
2.计算新的key的hash值
3.计算索引后,与原来索引处存放的元素相同,不能添加新的Node存放进去
4.对比新旧元素的hash值、地址值和内容是否相等
5.新的value替换旧的value,返回旧的value
6.table数组中的元素被改变
7.特殊情况
8.关于树化和剪枝的条件
(二)模拟触发扩容、树化情况
(三)关于扩容的补充说明
1.数组扩容可能会重新分配索引
2.扩容重新分配元素的索引后
一、HashMap概述

- Map接口的常用实现类:HashMap、HashTable和Properties。
- HashMap是Map接口使用频率最高的实现类
- HashMap是以key-value对的方式来存储数据(HashMap$Node类型)
- key不能重复,但是value可以重复,允许使用null键,但是null键只能使用一次,允许使用null值
- 如果添加相同的key,则会覆盖原来的key-value,等同于修改(key不会替换,value会替换)
- 与HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的,HashMap底层是 数组+链表+红黑树,注意:链表和红黑树是可以同时存在的
- HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有synchronized关键字修饰
二、HashMap添加重复键源码解析
Map map = new HashMap();
map.put("no1", "jack");
map.put("no2", "rose");
map.put("no1", "john");





HashMap 添加重复键时的核心流程:
- 计算键的哈希值,确定存储位置。
- 检查键是否已经存在,通过 hashCode() 和 equals() 方法判断。
- 如果键已经存在:键保持不变,不会更新,新的值会覆盖旧的值。
- HashMap 的设计原则:键的唯一性保证了当一个键已经存在时,添加相同的键会更新对应的值。
三、HashMap底层机制及源码剖析
HashMap底层有一个table表,table表是一个数组,数组中有链表或红黑树,每个结点就是一个HashMap$Node,该HashMap$Node实现了Map.Entry接口。当链表中存放的元素达到8,并且数组长度达到64时,该链表就会进行树化,即变为红黑树。红黑树的查询效率很高。
这就是为什么HashMap底层是[数组+链表+红黑树](JDK8以后)。JDK7之前的HashMap底层实现[数组+链表]。

(一)扩容机制(和HashSet相似)
更详细解析可以看我的往期文章:《JavaSE——集合5:Set(HashSet的底层原理)(重要!!!)》
- HashMap底层维护了Node类型的数组table,默认为null
- 当创建对象时,将加载因子(loadfactor)初始化为0.75
- 当添加key-value时,通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素,直接添加;如果该索引处有元素,继续判断该元素的key的hash值和传入的key的hash值是否相等,以及key的内容是否相等,如果相等,则直接替换value;如果不相等,需要判断是树结构还是链表结构,做出相应处理;如果添加时发现容量不够,则需要扩容。
- 第1次添加,则需要扩容table容量为16,临界值(threshold)为12(16*0.75)
- 之后再次进行扩容,则需要扩容table容量为原来的2倍(32),临界值为原来的2倍(32*0.75),即24,以此类推。
- 在JDK8之后,如果一条链表的元素个数超过TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)。
第一次添加:
HashMap map = new HashMap();
map.put("java", 10);
map.put("php", 10);
map.put("java", 20);
System.out.println(map);1.首先,调用构造器,初始化加载因子

2.初始化后table表为null

3.基本数据类型的装箱,转为一个对象

4.执行put方法
 5.计算key的hash值
5.计算key的hash值

6.返回并执行putVal方法
7.初次存放数据之前,判断table表是否为空,table=null,则进行扩容

8.执行resize方法
得到table数组的长度16,以及临界值12=16*0.75

table表就是Node

9.返回table表的长度

10.得到索引,索引位置为null,就放进去


11.放入索引位置后,继续判断是否需要扩容
modCount:通常用于记录数据结构自创建以来发生的修改次数。这里的“修改”通常指的是任何可能改变数据结构状态的操作,比如添加、删除或更新元素。
size:表示数据结构中当前存储的元素数量。
当size的数量不超过临界值,就不进行扩容
第二次添加:
1.基本数据类型进行装箱,转为一个对象

2.重新计算hash值


3.再次判断table数组是否为null

4.table数组不为null,则计算索引,索引位置没有元素,创建新的Node,添加元素

5.再次判断当前元素数量是否超过临界值

6.没有超过,返回null

第三次添加:
1.仍旧进行装箱操作

2.计算新的key的hash值

3.计算索引后,与原来索引处存放的元素相同,不能添加新的Node存放进去

4.对比新旧元素的hash值、地址值和内容是否相等

5.新的value替换旧的value,返回旧的value

HashMap的put()方法返回旧值而不是新值,主要是为了:
- 让调用者可以知道替换之前的旧值是什么,从而帮助判断是否发生了值的替换。
- 提供额外的上下文信息,以便调用者基于此做更多的逻辑处理。
- 新值已经由调用方传入,返回它并无实际意义。
6.table数组中的元素被改变

7.特殊情况
else {Node<K,V> e; K k;//辅助变量// 如果table的索引位置的key的hash相同和新的key的hash值相同// 并 满足(table现有的结点的key和准备添加的key是同一个对象 || equals返回真)// 就认为不能加入新的k-v
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;
else if (p instanceof TreeNode)//如果当前的table的已有的Node 是红黑树,就按照红黑树的方式处理e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {// 如果找到的结点,后面是链表,就循环比较for (int binCount = 0; ; ++binCount) {//死循环if ((e = p.next) == null) {//如果整个链表,没有和他相同,就加到该链表的最后p.next = newNode(hash, key, value, null);// 加入后,判断当前链表的个数,是否已经到8个,到8个,后// 就调用 treeifyBin 方法进行红黑树的转换if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash && // 如果在循环比较过程中,发现有相同的key,就break,替换value((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}
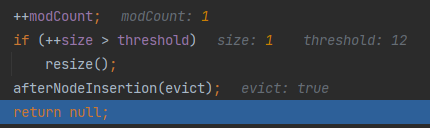
}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value; // 替换,key对应valueafterNodeAccess(e);return oldValue;}}++modCount;//每增加一个Node ,就size++if (++size > threshold[12-24-48])// 如果 size > 临界值,就扩容resize();afterNodeInsertion(evict);return null;
}8.关于树化和剪枝的条件
table数组的长度超过64,并且一条链表的元素为8,才进行树化,否则继续扩容。
红黑树的剪枝:删除元素到达一定程度,红黑树会重新转为链表

(二)模拟触发扩容、树化情况
代码示例:
public class HashMapSource2 {public static void main(String[] args) {HashMap hashMap = new HashMap();for (int i = 1; i <= 12; i++) {hashMap.put(new A(i), "hello");}hashMap.put("aaa", "bbb"); }
}class A {private int num;public A(int num) {this.num = num;}// 所有的A对象的hashCode都是100@Overridepublic int hashCode() {return 100;}@Overridepublic String toString() {return "\nA{" +"num=" + num +'}';}
}扩容前:

扩容后:

继续在链表上添加元素,扩容到64:

继续添加,链表进行树化:
树化前:

树化后:

(三)关于扩容的补充说明
注意:table数组并不会无限扩大
table容量最大值:2^30 = 1073741824
static final int MAXIMUM_CAPACITY = 1 << 30;临界值的最大值:2^31-1 = 2147483647
@Native public static final int MAX_VALUE = 0x7fffffff;
如果当前的数组容量(oldCap)已经达到或超过了 MAXIMUM_CAPACITY,那么HashMap将不再进行扩容操作,而是将临界值(threshold)设置为 Integer.MAX_VALUE,作为一个标记,表明HashMap已经达到了其可以容纳的最大元素数量的上限。
扩容是容量翻倍,重新分配的索引要么是原来的索引处,要么是原来索引 + 原来的数组长度处

1.数组扩容可能会重新分配索引

2.扩容重新分配元素的索引后

