港大和字节提出长视频生成模型Loong,可生成具有一致外观、大运动动态和自然场景过渡的分钟级长视频。
HKU, ByteDance|⭐️
港大和字节联合提出长视频生成模型Loong,该模型可以生成外观一致、运动动态大、场景过渡自然的分钟级长视频。选择以统一的顺序对文本标记和视频标记进行建模,并使用渐进式短到长训练方案和损失重新加权来克服长视频训练的挑战。
此外,Loong还会特别关注视频前几帧,以确保它们的质量不会被后面的帧所掩盖。最后,在生成视频时,Loong会不断调整和优化,以确保生成的视频既有趣又流畅。

相关链接
论文地址:http://arxiv.org/abs/2410.02757v1
项目主页:https://epiphqny.github.io/Loong-video/
论文阅读

摘要
生成几分钟内内容丰富的长视频是人们所期望的,但同时也是一项挑战。自回归大型语言模型 (LLM) 在自然语言处理领域生成连贯且较长的标记序列方面取得了巨大成功,而自回归 LLM 在视频生成方面的探索仅限于生成几秒钟的短视频。
本文深入分析了阻碍基于自回归 LLM 的视频生成器生成长视频的挑战。基于观察和分析提出了 Loong,这是一种新的基于自回归 LLM 的视频生成器,可以生成几分钟长的视频。具体来说,将文本标记和视频标记建模为自回归 LLM 的统一序列,并从头开始训练模型。提出了渐进式的从短到长的训练,并采用损失重新加权方案来缓解长视频训练的损失不平衡问题。
文章还进一步研究了推理策略,包括视频标记重新编码和采样策略,以减少推理过程中的错误积累。提出的 Loong 可以在 10 秒视频上进行训练,并可以扩展以根据文本提示生成分钟级长的视频,结果证明了这一点。
方法
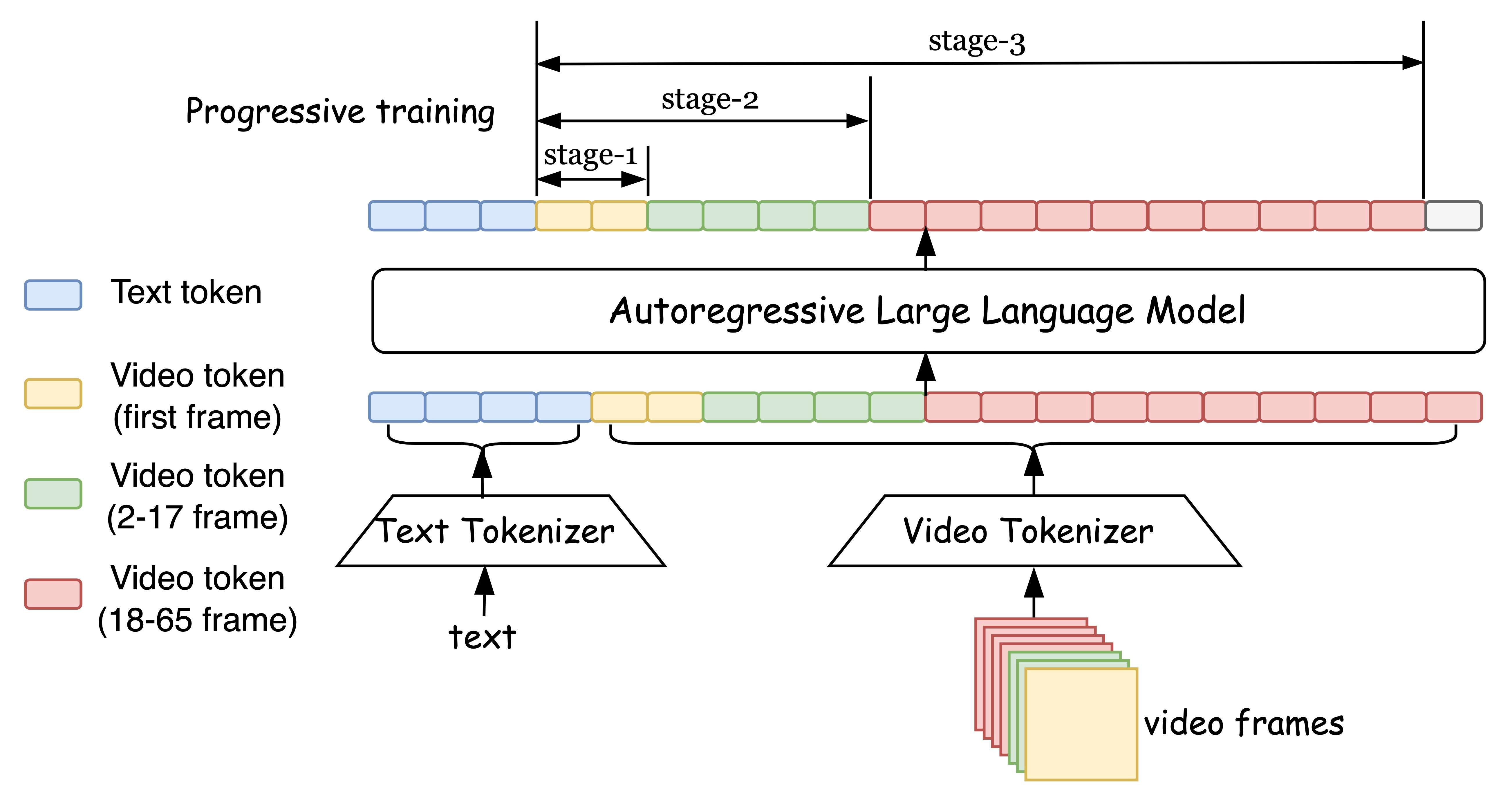
给定输入的文本标记,该模型会自回归地预测视频标记。所有文本和视频信息都被公式化为单向离散标记序列,其中模型根据前一个标记预测下一个标记。视频标记器用于将视频帧转换为离散视频标记。我们遵循渐进式训练流程来训练长视频。
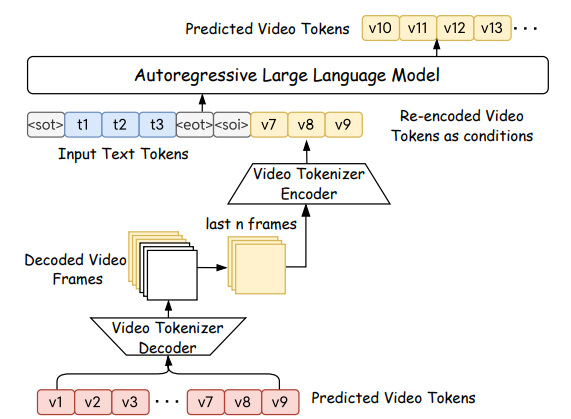
Loong 的推理过程。 给定输入文本,模型首先预测前 10 秒的视频标记(以 v1-v9 表示)。然后,此剪辑的最后 n 帧中的标记被解码为视频帧,并由视频标记器重新编码。这些重新编码的标记(v7-v9)与文本标记一起作为预测下一个剪辑的视频标记(v10-v13)的条件。标记预测、部分解码和重新编码的这种迭代过程可以将视频延长到训练时长之外,同时减轻质量下降。重复此过程,直到生成的视频达到所需长度。
实验
生成高分辨率视频

Prompt: Clown fish swimming through the coral reef

Prompt: A panda eating bamboo on a rock

Prompt: A koala bear playing piano in the forest
重建视频使用离散视频标记器。


左:原始视频,右:重构视频
生成的低分辨率短视频(128x128)

结论
文章提出了基于自回归LLM的视频生成模型 Loong,该模型可以生成外观一致、运动动态大、场景过渡自然的分钟级长视频。选择以统一的顺序对文本标记和视频标记进行建模,并使用渐进式短到长训练方案和损失重新加权来克服长视频训练的挑战。实验证明了该方法在生成分钟级长视频方面的有效性。