LLM基础概念:RAG
什么是RAG
在大语言模型时代,RAG指的是在回答问题或生成文本时,先从大规模文档库中检索相关信息,然后利用这些检索到的信息来生成响应或文本,从而提高预测的质量。RAG已被证明能显著提高回答的准确性,减少模型产生的幻觉,尤其是在知识密集型任务中。
RAG的好处
- 提高答案准确性:通过引用外部知识库中的信息,RAG可以提供更准确的回答
- 增加用户信任:用户可以通过引用的来源来验证答案的准确性
- 便于知识更新和引入特定领域知识:RAG通过结合LLMs的参数化知识和外部知识库的非参数化知识,有效的解决了知识更新的问题。
如何实现RAG
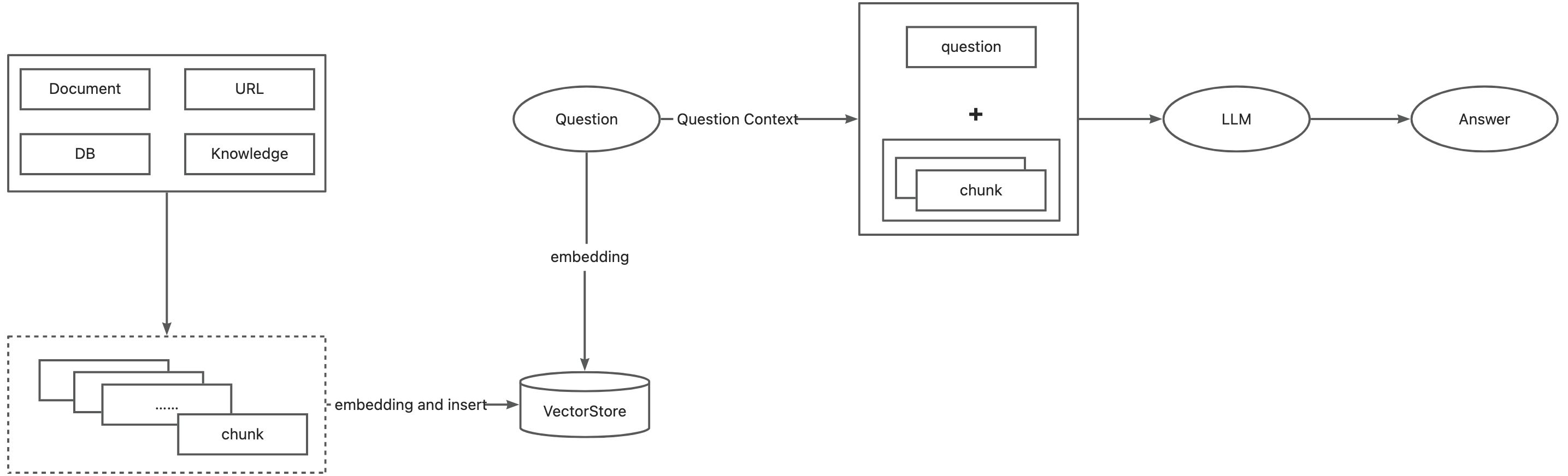
RAG如何做到效果最优
- 提高数据质量:
- 数据清洗:清理掉明显的噪音和错误数据提高数据的多样性和数量
- 知识库走知识图谱,建立概念之间的关系
- 数据清洗:清理掉明显的噪音和错误数据提高数据的多样性和数量
- 知识召回的质量:召回率和准确率
-
- 合理的chunking,多留一些overlap,保持语义性
- 召回采用多种手段:搜索+语义综合召回,提升召回匹配度
- 评测驱动
-
- 多调试,通过评测数据结果驱动调优;并且通过case study理解大模型进一步做出适配的调优策略。