Streamx基础讲解
一、简介
实时即未来。在实时处理领域,Apache Spark 和 Apache Flink 已经取得了巨大的进步,尤其是 Apache Flink 被普遍认为是下一代大数据流计算引擎。通过 Flink 和 Spark 的使用,我们发现从编程模型、启动配置到运维管理都有很多可抽象和共用的地方。为了固化这些经验并结合业内最佳实践,StreamX 诞生了。该项目的初衷是简化流处理,让开发者能够专注于核心业务,通过降低学习成本和开发门槛,提升流处理的易用性。
StreamX 规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式,提供了一系列开箱即用的 Connectors,标准化了配置、开发、测试、部署、监控、运维的整个过程。同时,StreamX 支持 Scala 和 Java 两套 API,致力于打造一个一站式的大数据平台,实现流批一体、湖仓一体的解决方案。
二、组成部分
StreamX 的整体架构由三大组件组成:streampark-core、streampark-pump 和 streampark-console。
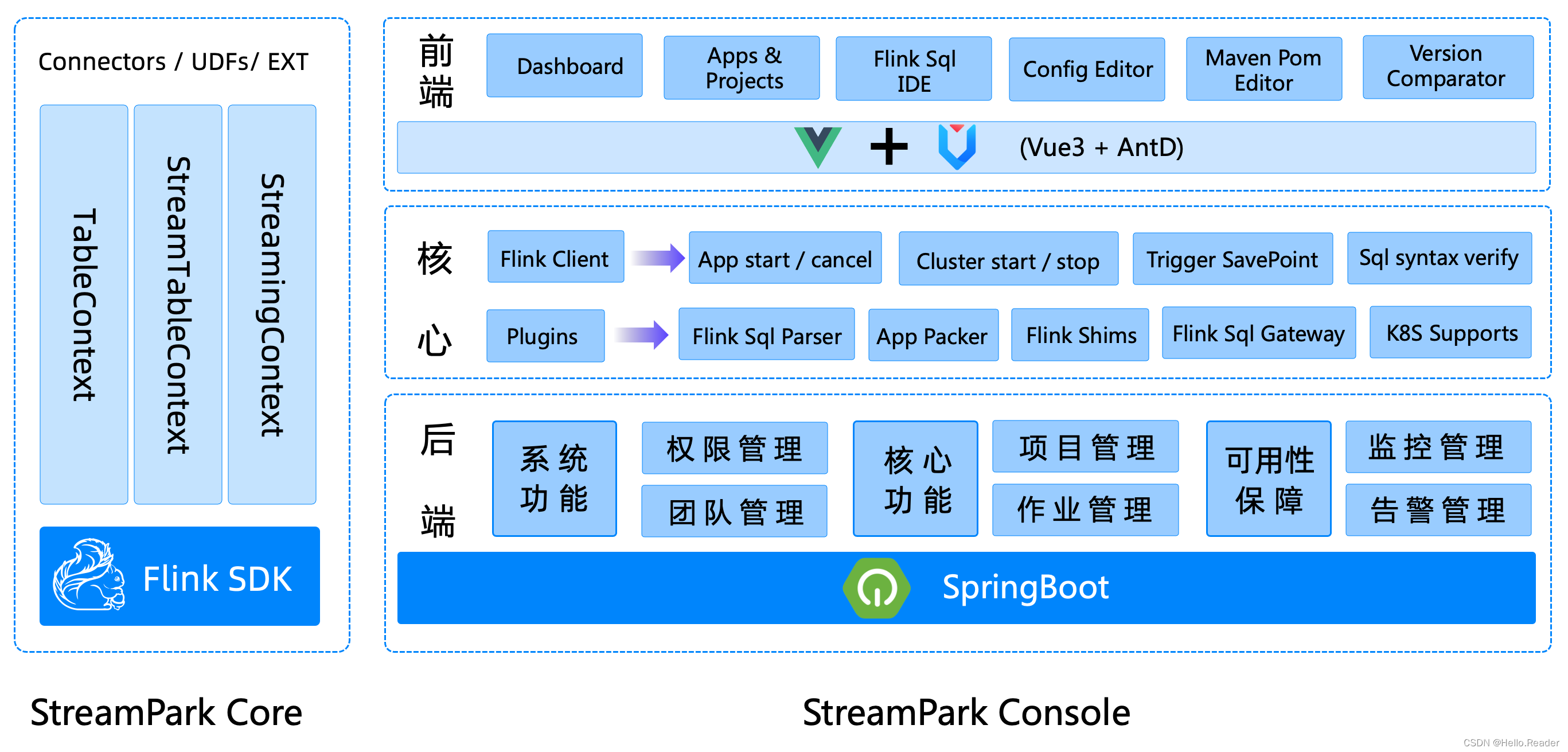
好的,我将进一步丰富这篇技术博客,提升其质量,包括更深入的背景介绍、架构分析、功能亮点以及更多实践性内容,以确保读者能够全面理解和掌握 StreamX 的基础概念。
一、简介
在如今的数据驱动世界中,实时数据处理已经成为各大企业的核心需求。无论是在金融、零售、物联网(IoT)还是互联网公司,实时数据处理能力都直接影响到业务决策的准确性和市场响应速度。在这个背景下,Apache Flink 和 Apache Spark 作为最主流的流处理引擎,推动了流计算领域的巨大进步,尤其是 Flink 被认为是下一代大数据流计算引擎。
然而,尽管 Flink 和 Spark 已具备强大的流处理能力,但它们的编程模型、运维管理、任务调度等方面依旧存在一定复杂性,这往往对开发者提出了较高的技术门槛。为了解决这些问题,我们基于 Flink 和 Spark 以及多年流处理领域的最佳实践,打造了 StreamX 框架。StreamX 的初衷是简化流处理开发和管理流程,降低学习成本,让开发者可以专注于核心业务逻辑的实现。
通过 StreamX,开发者能够快速上手流任务的开发、部署、监控和运维,从而实现更加高效的实时数据处理解决方案。
二、组成部分
StreamX 是一个围绕 Apache Flink 打造的流处理框架,其架构分为三大核心组件:streampark-core、streampark-pump 和 streampark-console。
1. streampark-core
streampark-core 是 StreamX 的核心模块,主要关注开发阶段的代码结构优化与配置管理。它通过约定优于配置的设计思想,规范了开发流处理任务的方式。以下是 streampark-core 的主要功能:
- 简化配置:
streampark-core提供了一套标准化的配置体系,开发者可以按照约定快速完成项目的配置,而无需为复杂的配置文件感到困扰。 - 增强的 API 支持:扩展了 Flink 的 DataStream API,提供了更多开箱即用的功能模块,帮助开发者更方便地与外部系统(如 Kafka、MySQL、HBase)集成。
- Flink SQL 与 DataStream 的融合:同时支持 Flink SQL 和 DataStream API,允许开发者根据业务场景选择合适的编程模型,同时降低了两者之间的切换成本。
2. streampark-pump
streampark-pump 是 StreamX 中的数据抽取模块,定位为一个类似于 FlinkX 的实时数据迁移和抽取工具。该模块的主要功能是利用 streampark-core 中的各类连接器(Connectors),从不同的数据源抽取数据,提供开箱即用的数据迁移能力。streampark-pump 的设计初衷是让开发者可以轻松构建数据管道,适用于从传统数据库、消息队列等不同来源抽取数据并进行实时处理。
3. streampark-console
streampark-console 是 StreamX 的管理控制台模块,也是其最具特色的部分。作为一个综合实时数据管理平台,streampark-console 提供了对 Flink 和 Spark 任务的低代码管理和运维支持,主要功能包括:
- 可视化管理:通过友好的用户界面,开发者可以快速提交、监控、暂停或终止 Flink 任务,而无需直接操作命令行。
- 项目编译与发布:集成了项目的编译和发布流程,支持多环境部署,并通过版本管理来保证任务的稳定性。
- 任务参数配置:支持为每个流任务设置自定义的参数,帮助实现更加灵活的任务控制。
- Savepoint 管理:支持自动生成和恢复 Flink 的 Savepoint,简化了流任务的容错处理。
- 火焰图(Flame Graph)分析:集成了 JVM Profiler,开发者可以通过火焰图直观地了解 Flink 任务的资源消耗情况,帮助进行性能调优。
- Flink SQL 支持:提供了 Flink SQL 任务的管理和监控功能,用户可以直接在控制台上编写和运行 SQL 查询,适合处理流数据的实时分析需求。
最终目标是将 streampark-console 打造成为一个低代码、一站式的实时数据平台,融合了流批处理一体化、实时数据仓库、湖仓一体等大数据解决方案。
三、环境要求
为了确保 StreamX 的高效运行,部署环境需要满足以下条件:
| 要求 | 版本 | 是否必须 | 其他说明 |
|---|---|---|---|
| 操作系统 | Linux | 是 | Windows 系统不支持 |
| Java | 1.8+ | 是 | |
| Maven | 3+ | 否 | 可选,用于项目编译 |
| Node.js | 最新版本 | 是 | 需要安装 Node.js 环境 |
| Flink | 1.12.0+ | 是 | Flink 版本必须是 1.12.x 或以上,且支持 Scala 2.11 |
| Hadoop | 2+ | 否 | 可选,若使用 Flink on YARN 需要 Hadoop 环境 |
| MySQL | 5.6+ | 否 | 可选,用于存储元数据 |
| Python | 2+ | 否 | 可选,火焰图功能需要 Python 环境 |
| Perl | 5.16.3+ | 否 | 可选,火焰图功能需要 Perl 支持 |
注意:StreamX 1.2.2 及之前版本只支持 Scala 2.11,1.2.3 版本及以后开始支持 Scala 2.11 和 Scala 2.12。
四、StreamX 的应用场景
1. 实时数据分析
在需要实时监控和快速响应的数据分析场景中,StreamX 提供了集成 Kafka 和 Flink 的流处理能力,适用于金融风控、用户行为分析等场景。例如,用户行为数据可以通过 Kafka 实时采集,利用 Flink 进行实时处理,并通过 StreamX 的可视化工具进行实时监控和分析。
2. 实时推荐系统
StreamX 还可以与机器学习模型集成,帮助开发者构建实时推荐系统。通过流式数据处理实时更新推荐模型,系统可以对用户的实时行为进行分析,并提供个性化的推荐服务。
3. 物联网数据处理
在物联网(IoT)场景中,设备产生的数据量巨大且需要实时处理。StreamX 能够帮助企业搭建实时数据监控平台,处理物联网设备的传感器数据并进行实时分析、告警和响应。
五、StreamX 的优势
相比于传统的流处理框架,StreamX 具有以下几个显著优势:
- 简化开发流程:StreamX 提供了标准化的配置文件和编程模型,极大降低了流处理任务的开发复杂度,尤其是对新手友好。
- 低代码开发:通过
streampark-console提供的可视化平台,开发者可以通过简单的拖拽和配置实现流任务的开发和管理,降低了对流处理技术的掌握门槛。 - 一站式管理:StreamX 集成了从开发、测试、部署到监控的一整套工具,开发者无需额外编写复杂的脚本即可轻松管理流任务。
- 高扩展性:支持与各种主流大数据组件(如 Kafka、MySQL、HBase)的集成,提供了灵活的扩展能力。
六、总结
StreamX 是一个强大且易用的流处理框架,它结合了 Flink 的流处理优势和最佳实践,简化了从开发到运维的整个过程。通过 streampark-core、streampark-pump 和 streampark-console 三大组件的支持,StreamX 帮助开发者更轻松地构建实时数据处理系统,适用于多种应用场景如实时分析、物联网、推荐系统等。
随着实时数据处理需求的日益增长,StreamX 的低代码特性、丰富的管理工具和强大的扩展能力,使其成为了企业在实时流处理领域中的一站式解决方案。无论是流批处理一体化,还是湖仓一体,StreamX 都能为企业提供高效、灵活的流数据处理支持。