2023中国研究生创新实践系列大赛“华为杯”第二十届中国研究生数学建模竞赛E题优秀论文-问题1
出血性脑卒中临床智能诊疗模型的建立
摘 要:
构建智能诊疗模型,明确导致出血性脑卒中预后不良的危险因素,实现精准个性化的 疗效评估和预后预测对改善患者预后、提升其生活质量、优化临床决策具有着重要意义。患者的 CT 影像数据包含了丰富的患者血肿和水肿信息,因此成为患者预后模型建立的重 要依据。本文通过分析患者临床信息探讨了导致出血性脑卒中预后不良的影像因素。利用 机器学习的方法来预测患者预后情况并对其准确性进行了评估;在此基础上,通过比较多 个回归模型建立了效果最佳的回归算法,并绘制了水肿体积随时间进展模式曲线;最后建 立多种预测模型,从多个维度帮助患者制定有效的治疗方案。
针对问题一 (a),我们对数据进行了预处理,剔除数据中存在的缺失值、异常值、异常 变量和异常样本。在变量筛选过程中,考虑了变量之间的线性和非线性关系。使用 SPSS 分析数据之间相关关系,极大提高了有效数据利用率,能够更准确地预测患者发病后 48 小时内是否发生血肿扩张情况和发生时间。针对问题一 (b) 我们将朴素贝叶斯分类(NBM) 模型和二元线性回归模型有机结合建立新模型对患者发生血肿扩张的概率进行预测,取得 显著成果。
针对问题二 (a),我们对数据进行处理后分别采用了局部加权回归模型和非线性最小 二乘法对全体患者水肿体积随时间进展曲线进行了拟合。根据残差的值选择非线性最小二 乘法作为回归模型,得到了输出函数及总体的残差。针对问题二 (b),我们基于问题 2(a) 已 处理的数据进行降维,再根据离散数据类似球形且无人工标注类别,我们选择 K -means 聚类算法对数据进行分类,再用手肘法确定最优簇数量,最后分为了三个亚组。根据散点 图的形状我们假设了一个非线性函数来分别拟合三个亚组的回归模型,得出三个函数,其 R 方值分别为 0.98165,0.9493,0.92217。根据散点图的形状可以粗略判断三组患者分别为 1,治疗周期较长,病情不能确定。2,水肿体积减小较快,病情趋于好转。3,水肿体积趋 于增长,病情趋于恶化。最后得出不同亚组的残差。针对问题二 (c),在假设各种治疗方法 互相独立的情况下,采用各种治疗方法作为自变量,采用每个患者在每两个检查点之间斜 率的最小值作为拟合函数的因变量,通过多元线性回归模型确定不同治疗方法的权重,通过比较治疗方法的权重得出各种治疗方法对水肿体积进展模式的影响:1,对治疗周期较 长,病情不能确定患者的治疗效果:镇静、镇痛治疗 > 营养神经 > 止血治疗 > 降颅压治疗 > 止吐护胃 > 降压治疗 > 脑室引流。2,对水肿体积减小较快,病情趋于好转患者的治疗 效果:脑室引流 > 止血治疗 > 营养神经 > 镇静、镇痛治疗 > 止吐护胃 > 降颅压治疗 > 降 压治疗。3,水肿体积趋于增长,病情趋于恶化患者的治疗效果:营养神经 > 降颅压治疗 > 止血治疗 > 镇静、镇痛治疗 > 止吐护胃 > 降压治疗 > 脑室引流。针对问题二 (d),延用了 问题二 (c) 中的模型计算水肿体积与治疗方法的函数,得到 R 方值为 0.91553,水肿体积与 治疗方法函数的 R 方值为 0.93522,通过计算得出血肿体积和水肿体积之间的相关系数为 0.3052,说明血肿体积和水肿体积之间存在着较弱的正相关关系。
针对问题三 (a)、(b),我们基于首次影像建立决策树回归模型(DTR),使用分类回归 树算法(CART)针对患者 90 天 mRS 评分进行训练、预测,最后的模型预测准确率达到 100%。针对问题三 (c),通过分析血性脑卒中患者的预后(90 天 mRS)和个人史、疾病史、 治疗方法及影像特征等关系联系,我们对高维度的数据进行主成分分析(PCA)数据降维 处理,建立起相关性分析模型,探索出特征之间数学关系,帮助我们系统地提出临床决策 建议。
关键字:出血性脑卒中预后,朴素贝叶斯,非线性最小二乘法,K-means 聚类,决策树回 归,相关性分析


-
问题重述
-
1 问题背景
脑卒中是我国成年人致死、致残的首位原因,脑卒中后 60% − 80% 的患者仍有不同程 度的功能障碍 [1]。脑卒中不仅给社会带来沉重的医疗负担,也极大加重了患者的健康负 担。因此,发掘出血性脑卒中的发病风险,整合影像学特征、患者临床信息及临床诊疗方 案,精准预测患者预后,并据此优化临床决策具有重要的临床意义。出血性脑卒中后,血肿范围扩大是预后不良的重要危险因素之一。因此,监测和控制 血肿的扩张是临床关注的重点之一。此外,血肿周围的水肿作为脑出血后继发性损伤的标 志。综上所述,针对出血性脑卒中后的两个重要关键事件,即血肿扩张和血肿周围水肿的 发生及发展,进行早期识别和预测对于改善患者预后、提升其生活质量具有重要意义。期望能够基于患者影像信息,联合患者个人信息、治疗方案和预后等数据,构建智能 诊疗模型,明确导致出血性脑卒中预后不良的危险因素,实现精准个性化的疗效评估和预 后预测。
-
2 需要解决的问题
通过对真实临床数据的分析,研究出血性脑卒中患者血肿扩张风险、血肿周围水肿发 生及演进规律,最终结合临床和影像信息,预测出血性脑卒中患者的临床预后。本文主要 考虑以下几个问题:
问题一:对血肿扩张风险相关因素进行探索建模
在 (a) 问中我们要根据患者 sub001 至 sub100 的各时间点的血肿体积值判断发病后 48 小时内是否发生血肿扩张事件,并且记录发生血肿扩张的时间。是否发生血肿扩张根据后 续检查比首次检查绝对体积增加 ≥ 6mL 或相对体积增加 ≥ 33% 来判断。
在 (b) 问中我们以是否发生血肿扩张事件为目标变量,注意与 (a) 问中的发病后 48 小 时内是否发生血肿扩张事件进行区分,基于患者 sub001 至 sub100 的个人史,疾病史,发 病及治疗相关特征、影像检查结果(只包含对应患者首次影像检查记录)等变量,构建模 型预测所有患者(sub001 至 sub160)发生血肿扩张的概率。
问题二:对血肿周围水肿的发生情况进展进行建模,并探索治疗干预和水肿进展的关 联关系
在 (a) 问中根据于患者 sub001 至 sub100 的和时间点的水肿体积值,构建一条全体患 者水肿体积随时间进展曲线 y = f(x)(x 为发病至影像检查时间,y 为水肿体积),并计算患 者 sub001 至 sub100 真实值和所拟合曲线之间存在的残差。
在 (b) 问中我们探索患者水肿体积随时间进展模式的个体差异,要构建 3-5 各不同亚 组的人群,并构建各亚组的水肿体积随时间进展曲线,并计算患者 sub001 至 sub100 真实 值和曲线间的残差。
在 (c) 问中构建模型,分析不同治疗方法对水肿体积进展模式的影响。在 (d) 为中构建模型,分析血肿体积、水肿体积及治疗方法三者之间的关系。
问题三:探索出血性脑卒中患者预后预测及关键因素
在 (a) 问中根据患者 sub001 至 sub100 个人史、疾病史、发病相关及首次影像结果构建 预测模型,预测患者(sub001 至 sub160)90 天 mRS 评分。在 (b) 问中根据患者 sub001 至 sub100 所有信息,包括个人史,疾病史,发病相关、治疗 方法、首次及随访的影像结果等,构建预测模型,预测所有含随访影像检查的患者(sub001 至 sub100,sub131 至 sub160)90 天 mRS 评分。在 (c) 问中构建模型分析出血性脑卒中患者的预后(90 天 mRS)和个人史、疾病史、 治疗方法及影像特征等关联关系,并为临床相关决策提出建议。
2. 数据说明与异常数据和非数值数据处
2 . 1 数据说明
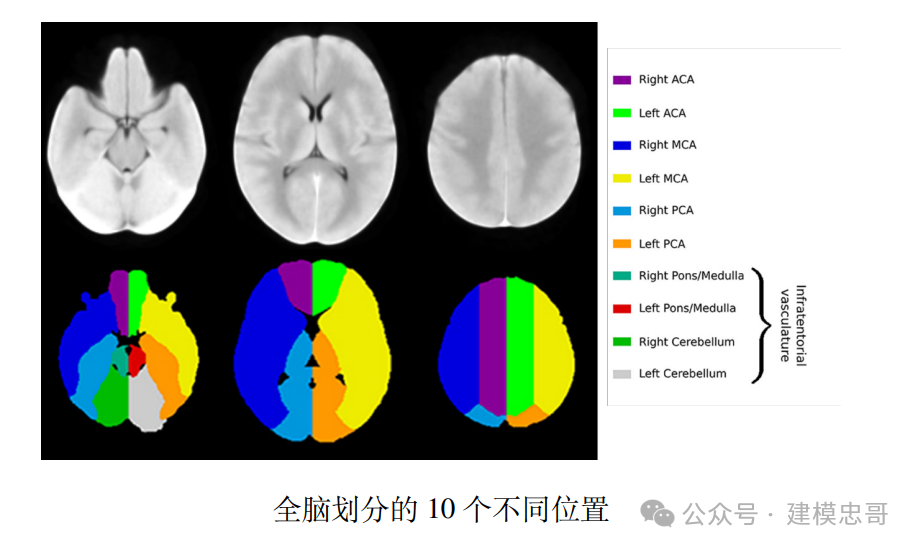
“表 1-患者列表及临床信息”为我们提供了患者的首次影像流水号、个人史、“脑出血 前 mRS 评分”、“90 天 mRS”、“发病到首次影像检查时间间隔”、治疗方案。“表 2-患者影像信息血肿及水肿的体积及位置”为我们提供了患者各个时间点 (首次 +随访) 的血肿和水肿的体积及其分布位置。在血肿、水肿的体积及其分布位置中,将全 脑划分为了 10 个不同位置:包括 ACA 大脑前动脉,MCA 大脑中动脉,PCA 大脑后动脉, Pons/Medulla 脑桥/延髓,Cerebellum 小脑 (Schirmer, Giese et al. 2019),具体如下图所示。
“表 3-患者影像信息血肿及水肿的形状及灰度分布”为我们提供了患者各个时间点(首 次+随访)的血肿和水肿的形状特征及灰度分布。灰度特征是基本的度量值,反映目标区 域内体素强度的分布;形状特征是对目标区域三维形状描述。
“附表 1-检索表格-流水号 vs 时间”为我们所有流水号 (首次+随访) 所对应的具体影 像检查时间点。
2 . 2 异常数据处理和非数值数据处理
异常数据处理:“表 1-患者列表及临床信息”中“sub074”的“入院首次影像检查流水号”填错为其 “随访 1 流水号”,将其“入院首次影像检查流水号”更正为“20180719000020”。“sub131” 和“sub132”实际上为“sub003”和“sub004”患者,“sub131”和“sub132”患者的缺失 数据我们将用“sub003”和“sub004”的相关数据进行弥补。“表 3-患者影像信息血肿及水肿的形状及灰度分布随访数据”中部分随访影像是对不 上患者流水号的,可能是非本文数据集中患者的影像,我们将做遗弃处理。
非数值数据处理:在本文所给的数据中非数值数据有两列,分别是“性别”和“血压”。对于“性别”,令性别“男”为“1”,性别“女”为“0”。对于“血压”,根据中国高血压防治指南,将高血压分为三级,分别是:一级:收缩压 为 140 − 159mmHg 或舒张压为 90 − 99mmHg;二级:收缩压为 160 − 179mmHg 或舒张压 为 100 − 109mmHg; 三级:收缩压 ≥ 180mmHg 或舒张压 ≥ 110mmHg。根据“血压”数据, 我们输出患者高血压等级 0, 1, 2, 3 代替“血压数据”。
3. 模型假设
• 患者完全服从治疗方法,无主观选择治疗方法的意愿。
• 所有治疗措施对不同病患的效果一样。
• 治疗方法之间不会相互影响,独立生效。
• 治疗方法从首次影像检查时间持续到最后一次随访。
• 在问题二 (c) 中水肿体积只受治疗方法的影响。
• 在问题三中患者的数据类个人史、发病史、治疗方案、影像信息之间相互独立。
4. 问题一
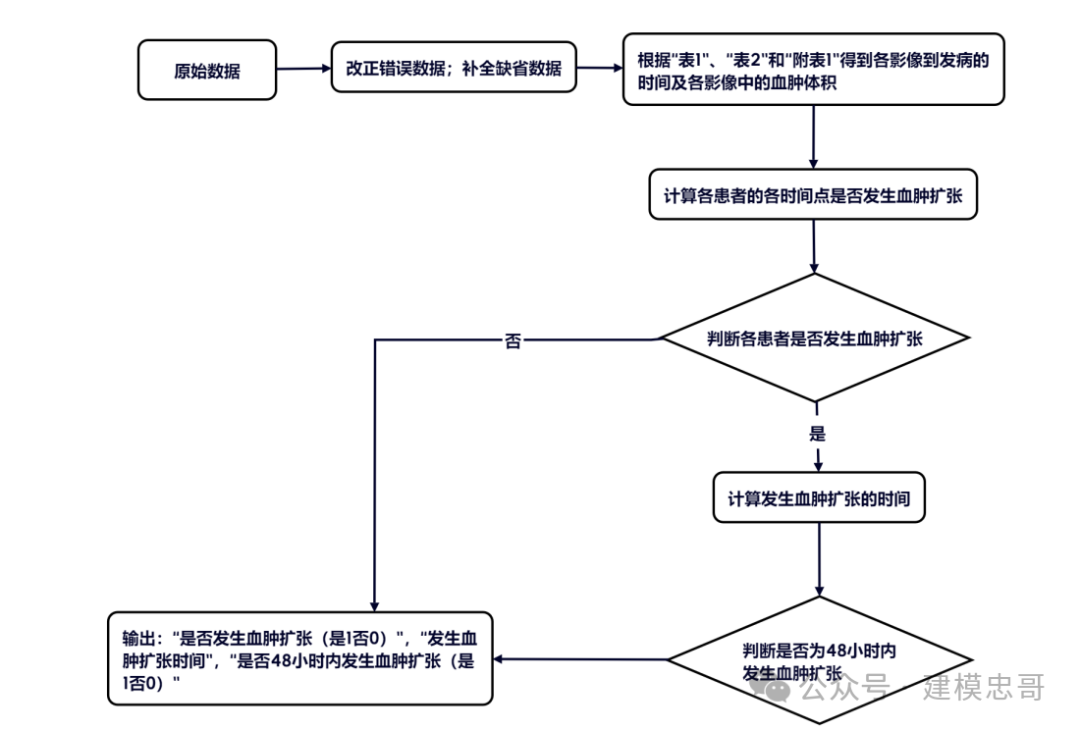
4 . 1 问题一 (a) 的分析与求解 根据题目要求, 首先需要判断每个患者是否发生了血肿扩张事件。根据定义, 如果后续 检查的血肿体积比首次检查增加 ≥ 6mL 或 ≥ 33%,则判断为发生了血肿扩张。
具体判断步骤: 1. 从“表 1-患者列表及临床信息”中提取每个患者的“入院首次影像检查流水号”;
2. 根据“入院首次影像检查流水号”在“附表 1-检索表格-流水号 vs 时间”中查找对应患 者的各次检查的时间点,包括“入院首次检查时间点”和“随访时间点”;
3. 计算发病到各次时间点的时间间隔,计算公式为: 发病到该影像的时间间隔 = 随访时间点−入院首次检查时间点+发病到首次影像检查时间间隔;
4. 在“表2-患者影像信息血肿及水肿的体积及位置”中找到每个随访各时间点的“HM_volume” 血肿体积值;
5. 依次计算每次随访检查血肿体积与首次检查血肿体检的变化量和变化百分比,如果变 化量 ≥ 6mL 或变化百分比 ≥ 33%, 则记为发生血肿扩张;
6. 判断患者是否在在院期间发生血肿扩张;
7. 针对有发生血肿扩张的患者找到其最早发生血肿扩张的时间;
8. 判断有发生血肿扩张的患者是否是 48 小时内发生的,并记录其发生时间。
问题一 (a) 流程图如下图 (4..1) 所示:
得到结果如下图 (4..2) 所示 (仅展示 sub001-sub020 患者的结果,其余结果在“表 4-答 案文件”中查看):
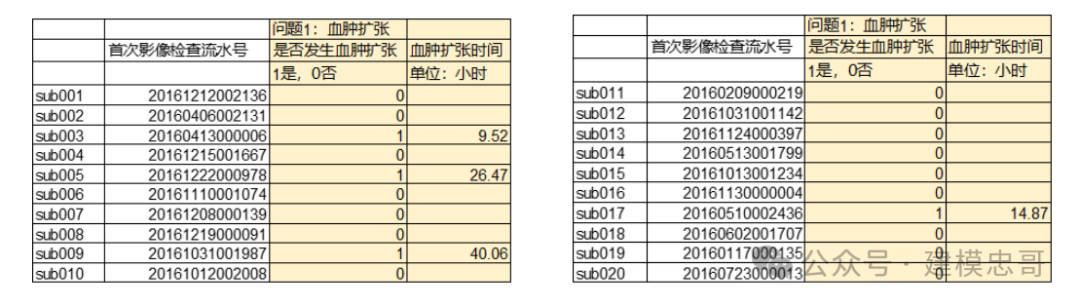
图 2 问题一 (a) 的 sub001-sub020 患者是否 48 小时内发生血肿扩张和血肿扩张时间
4 . 2 问题一 (b) 的分析
根据题目要求我们以是否发生血肿扩张事件为目标变量,与 (a) 问中的发病后 48 小时 内是否发生血肿扩张事件进行区分,(b) 问是否发生血肿扩张事件不受时间限制。基于患 者 sub001 至 sub100 的个人史,疾病史,发病及治疗相关特征、影像检查结果(只包含对 应患者首次影像检查记录)等变量,构建模型预测所有患者(sub001 至 sub160)发生血肿 扩张的概率。
我们将先基于问题一 (a) 所得到的字段“是否发生血肿扩张”(是 1 否 0) 作为目标变 量,从“表 1”中获得患者的个人史、疾病史、发病及治疗相关特征 (字段 E-W),从“表 2”中获取患者首次影像检查结果血肿及水肿的体积及位置 (字段 C 至 X),将患者的“入 院首次影像检查流水号”与“表 3”中“ED”表和“Hemo”表的“流水号”进行匹配获得 患者的首次影像信息血肿及水肿的形状及灰度分布 (字段 C-AG)。
基于以上所述数据的前一百行数据,即患者 sub001 至 sub100 的数据,我们首先将数 据类别进行判断,将其分为离散数据和连续数据,对于离散数据我们将运用伯努利朴素贝 叶斯算法,对于连续数据我们将运用高斯朴素贝叶斯算法,最后我们将得到两种算法给出 的患者发生血肿扩张事件的概率。还是以“是否发生血肿扩张”(是 1 否 0) 作为目标变量, 将两种算法给出的患者发生血肿扩张事件的概率作为输入,对其进行线性回归,得到离散 数据大类和连续数据大类对发生血肿扩张事件所贡献的权重。依据该权重,得到最终的预 测模型。即可得到在全体患者 (sub001 至 sub160) 发生血肿扩张的概率。
问题一 (b) 流程图如下图 (4..3) 所示:
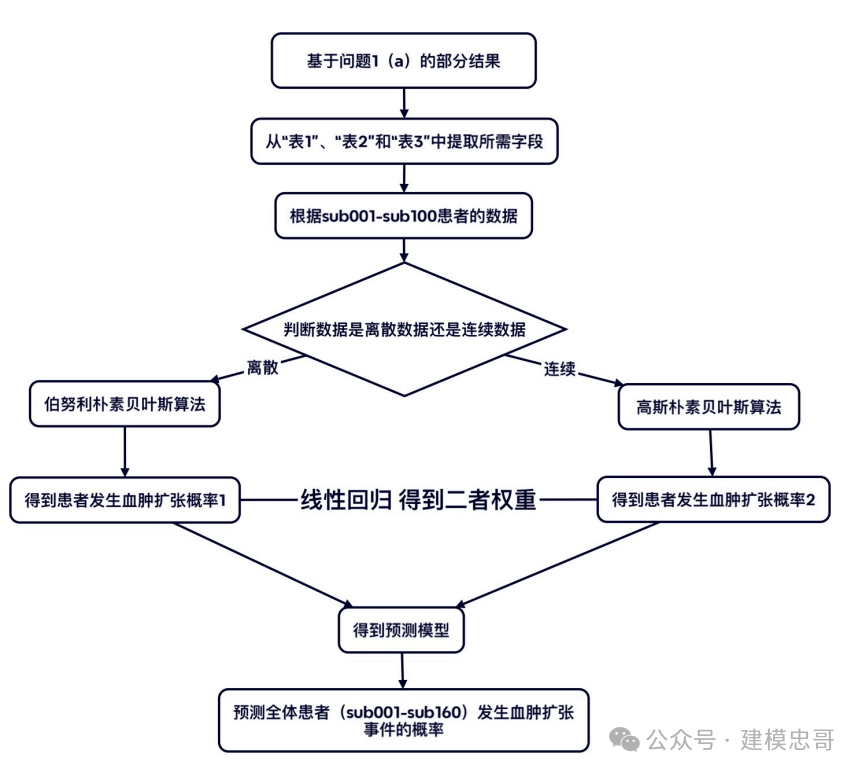
图 3 问题 1(b) 思路流程图
4 . 3 问题一 (b) 的模型建立
贝叶斯分类算法是以贝叶斯原理为基础, 使用概率统计的知识对样本数据集进行分类。贝叶斯分类算法的误判率很低。其特点是结合先验概率和后验概率, 既避免了只使用先验 概率的主观偏见, 也避免了单独使用样本信息的过拟合现象。
朴素贝叶斯算法 [2] 是基于贝叶斯定理与特征条件独立假设的分类方法, 是经典的机 器学习算法之一。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝 叶斯模型 (Naive Bayesian Model, NBM) 。和决策树模型相比, 朴素贝叶斯分类有着坚实的 数学基础和稳定的分类效率。同时, 朴素贝叶斯模型所需估计的参数很少, 对缺失数据不太 敏感, 算法也比较简单。
理论上, 朴素贝叶斯模型具有较小的误差率。朴素贝叶斯算法适用于维度非常高的数据集。朴素贝叶斯的基本方法是:在统计数据 的基础上,依据条件概率公式计算当前特征的样本属于某个分类的概率, 选择最大的概率 分类。对于给出的待分类项, 求解在此项出现的条件下各个类别出现的概率, 哪个最大, 就 认为此待分类项属于哪个类别。
在本题中,我们将发生血肿扩张和不发生血肿扩张作为两个待分类项,不判断其属于 哪个待分类项,只取其属于发生血肿扩张该分类项的概率作为患者发生血肿扩张的概率。
针对本题所给的数据,我们将数据是否为二项分布进行分类,分别应用伯努利朴素贝 叶斯算法和高斯朴素贝叶斯算法对患者发生血肿扩张的概率进行计算。两个算法将各自得 到患者发生血肿扩张的概率。继续是以“是否发生血肿扩张”作为目标变量,将两种算法 给出的患者发生血肿扩张事件的概率作为输入,对其进行线性回归,得到离散数据大类和 连续数据大类对发生血肿扩张事件所贡献的权重。依据得到的权重,即可得到在全体数据 的预测下发生血肿扩张的概率。
4 . 3 . 1 伯努利朴素贝叶斯
伯努利朴素贝叶斯适用于离散变量,故我们将数据中的“性别”、“高血压病史”、“卒 中病史”、“糖尿病史”、“房颤史”、“冠心病史”、“吸烟史”、“脑室引流”、“止血治疗”、“降 颅压治疗”、“降压治疗”、“镇静、镇痛治疗”、“止吐护胃”和“营养神经”应用伯努利朴 素贝叶斯算法。
伯努利朴素贝叶斯假设特征的先验概率为二元伯努利分布,试验 E 只有两个可能的结 果:A 与 A −,在本题中结果为发生血肿扩张和不发生血肿扩张,E 称为伯努利试验。伯努 利朴素贝叶斯适用于离散变量,其假设各个特征 xi 在各个类别 y 下是服从 n 重伯努利分 布(二项分布)的,因为伯努利试验仅有两个结果,因此算法会先对特征值进行二值化处 理(假设二值化的结果为 1 与 0 ),即
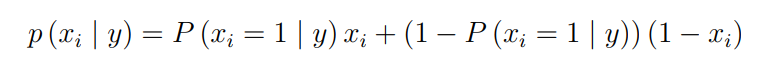
在训练集中, 会进行如下估计:

4 . 3 . 2 高斯朴素贝叶斯
高斯朴素贝叶斯 [3] 适用于连续变量, 故我们将数据中的“年龄”、“脑出血前 mRS 评 分”、“高血压程度”、“发病到首次影像检查时间间隔”和所有首次影像信息应用高斯朴素 贝叶斯算法。其假定各个特征 xi 在各个类别 y 下服从正态分布, 算法内部使用正态分布的 概率密度函数来计算概率,公式如下:
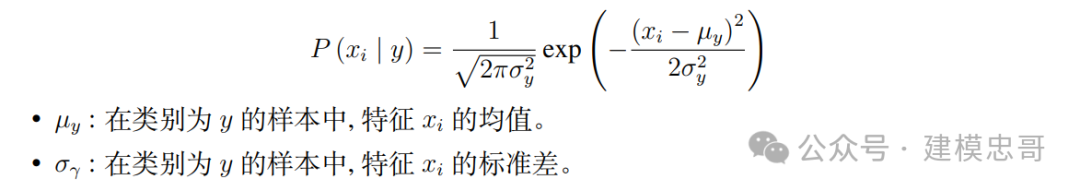
4 . 3 . 3 线性回归
线性回归 [4](Linear Regression)指采用线性方程作为预测函数, 对特定的数据集进行 回归拟合, 从而得到一个线性模型。若数据集中有两个特征 x1 和 x2, 在本题中即为伯努利 朴素贝叶斯预测的概率结果和高斯朴素贝叶斯预测的概率结果,那么此时需要用到二元线 性回归模型, 它的预测函数为:
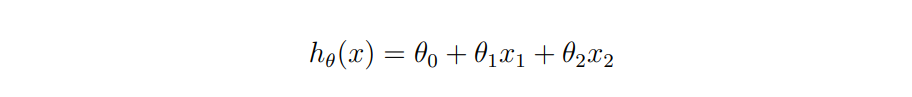
对应的损失函数为:
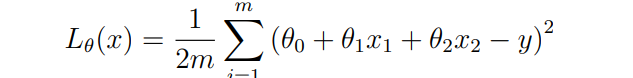
故, 用上式对三个参数求导可得:
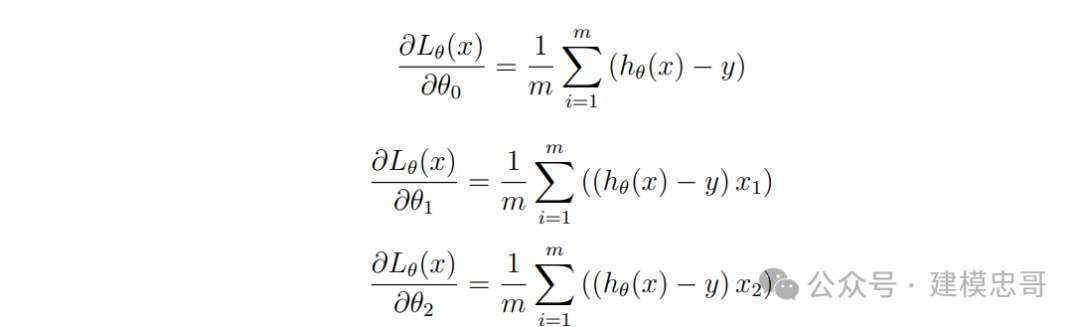
同样地, 二元线性回归模型也是使用梯度下降算法, 通过多次迭代更新参数 θ0、θ1 和 θ2 的 值, 从而使得它的损失函数值越来越小。其中更新参数 θ0、θ1 和 θ2 的公式分别为
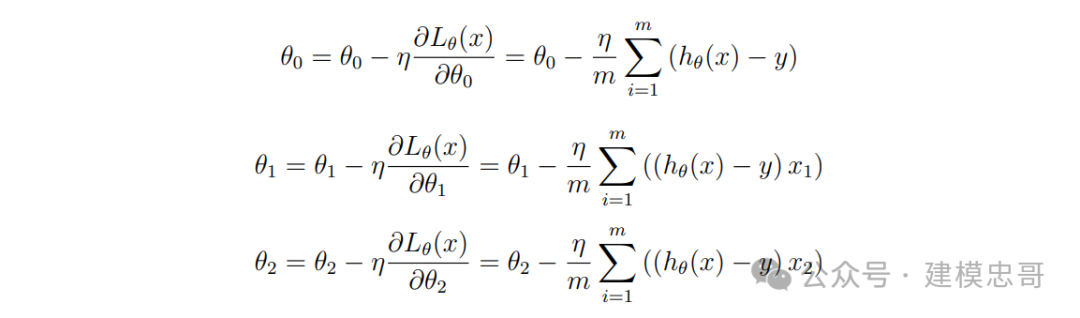
其中, η 为学习率, 每轮需要给 θ0、θ1 和 θ2 同时更新值, 直到迭代次数达到一定数量或者损 失函数 Lθ(x) 的值足够小甚至等于 0 为止。
4 . 4 问题一 (b) 的结果 根据上述我们建立的模型,我们得到患者发生血肿扩张的概率,结果如下图 (4..4) 所 示 (仅展示 sub101-sub120 患者的结果,其余结果在“表 4-答案文件”中查看),并额外展 示患者事实上是否发生血肿扩张事件 (是 1 否 0)。
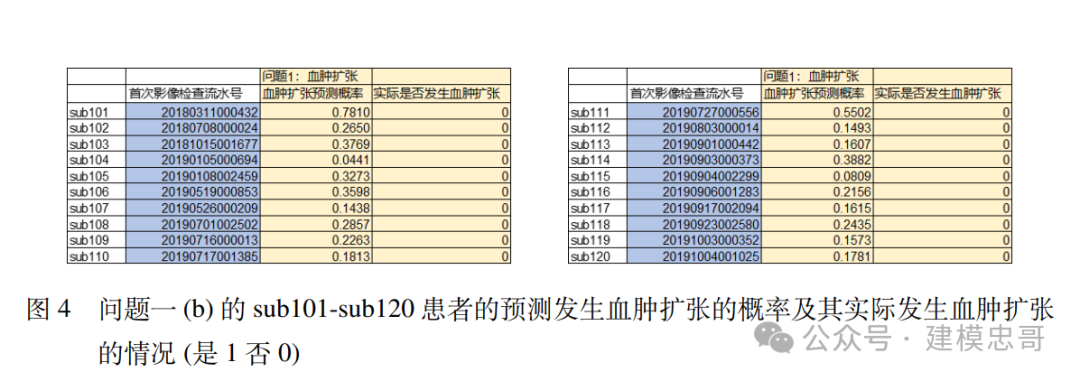
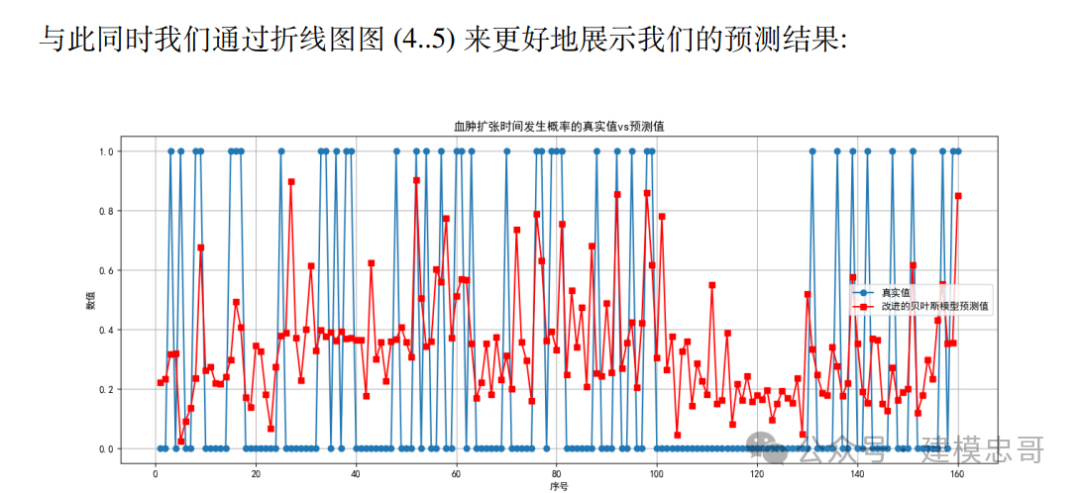
图 5 蓝色为实际发生血肿扩张情况 (是 1 否 0);红色为预测发生血肿扩张的概率 (取值范 围为 0 − 1)。问题一 (b) 的全体患者 (sub001-sub160) 的预测发生血肿扩张的概率及 其实际发生血肿扩张的折线图