基于C++网络编程入门学习(一)-- Linux环境下的C++程序编译与运行
基于C++网络编程入门学习(一)-- Linux环境下的C++程序编译与运行
- Linux环境下编译C++程序入门
- 几个VSCode插件安装
- 静态库与动态库
- 静态库
- 动态库
- makefile
- 不用makefile编译运行
- 利用makefile编译运行
- cmake
- gdb代码调试入门
Linux环境下编译C++程序入门
为了方便编写和调试C++程序,可以让vscode通过ssh命令远程连接ubuntu虚拟机。
为了确保能够编译C++程序,还需要在ubuntu虚拟机中安装好C++环境。
经过上述准备,我们可以按照如下步骤开始我们的Linux环境下编译C++程序的入门。
-
准备一个最简单的C++程序
#include<iostream> using namespace std; int main() {cout << "hello c++ and linux\n";return 0; }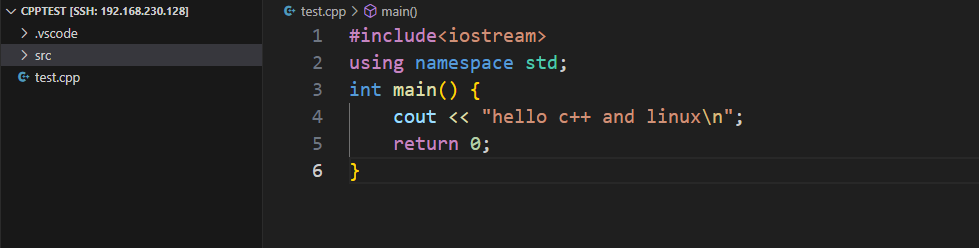
-
利用Linux命令编写和编译C++程序
编译并运行C++程序:
g++ -o test test.cpp./test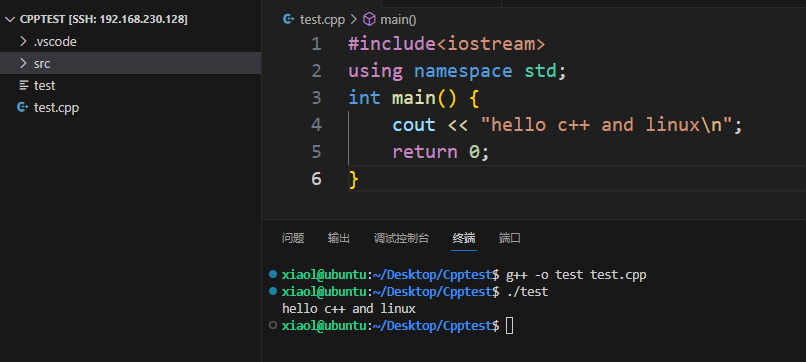
在此,我们完成了Linux环境下的第一个C++程序编写。
几个VSCode插件安装
静态库与动态库
在实际开发中,把通用的函数和类分文件编写,称之为库,在其他的程序中,可以使用库中的函数和类。
一般来说,通用的函数和类不提供源代码文件,而是编译成二进制文件。
库的二进制文件有两种:静态库和动态库。
静态库
-
制作静态库
g++ -c -o lib 库名.a 源代码文件清单 -
使用静态库
不规范的做法:
g++ 选项 源代码文件名清单 lib 库名.a规范的做法:
g++ 选项 源代码文件名清单 -l库名 -L文件名所在的目录名
动态库
-
制作动态库
g++ -fPIC -shared -o lib 库名.so 源代码文件清单 -
动态库静态库
不规范的做法:
g++ 选项 源代码文件名清单 动态库文件名规范的做法:
g++ 选项 源代码文件名清单 -l库名 -L库文件所在的目录名运行可执行程序的时候,需要提前设置
LD_LIBRARY_PATH的环境变量
makefile
在实际开发中,项目的源代码文件比较多,按类型、功能、模块分别存放在不同的目录和文件中,哪些文件需要先编译,那些文件后编译,那些文件需要重新编译,还有更多更复杂的操作。
make是一个强大的实用工具,用于管理项目的编译和链接。make需要一个编译规则文件makefile,可实现自动化编译。
makefile具体使用例子
代码举例
main.cpp
#include <iostream>
#include "functions.h"
using namespace std;int main()
{printhello();cout << "This is main:" << endl;cout << "The factorial of 5 is: " << factorial(5) << endl;return 0;
}
factorial.cpp
#include "functions.h"int factorial(int n)
{if(n == 1)return 1;elsereturn n * factorial(n-1);
}
printhello.cpp
#include <iostream>
#include "functions.h"using namespace std;void printhello()
{int i;cout << "Hello world" << endl;
}
functions.h
#ifndef _FUNCTIONS_H_
#define _FUNCTIONS_H_
void printhello();
int factorial(int n);
#endif
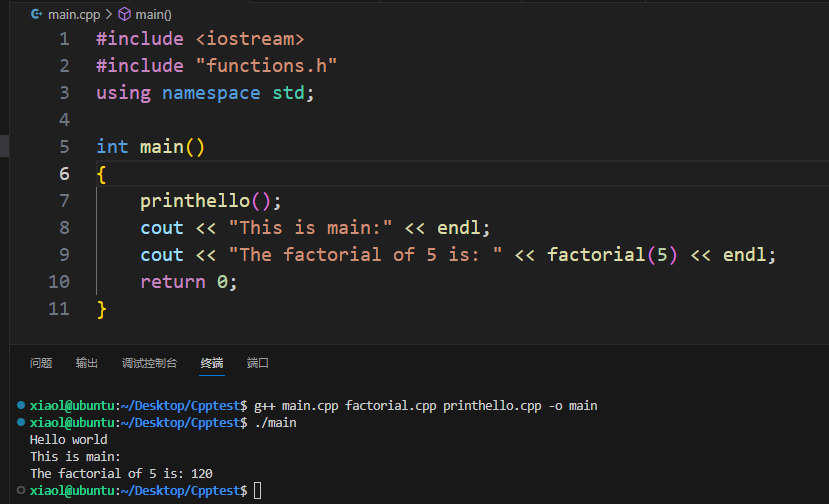
不用makefile编译运行
g++ main.cpp factorial.cpp printhello.cpp -o main
./main
利用makefile编译运行
首先在linux中安装make命令
apt-get install ubuntu-make
-
法一
# VERSION 1 # hello为生成的可执行文件,依赖于后面的三个.cpp文件 # g++前面加一个TAB的空格 hello: main.cpp printhello.cpp factorial.cppg++ -o hello main.cpp printhello.cpp factorial.cpp然后编译并运行
make ./hello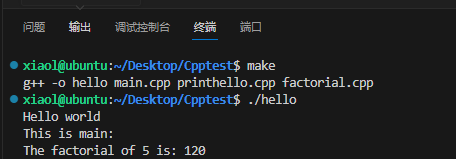
-
法二
# VERSION 2 CXX = g++ # 指定编译器 TARGET = hello OBJ = main.o printhello.o factorial.o # make时执行g++ 先找TARGET,TARGET不存在找OBJ,OBJ不存在,编译三个.cpp文件生成.o文件 # 然后再编译OBJ文件,生成可执行文件hello $(TARGET): $(OBJ) # TARGET 是依赖于 OBJ 这些文件$(CXX) -o $(TARGET) $(OBJ) # main.o这样来的,编译main.cpp生成 main.o: main.cpp$(CXX) -c main.cpp printhello.o: printhello.cpp$(CXX) -c printhello.cpp factorial.o: factorial.cpp$(CXX) -c factorial.cpp然后编译并运行
make ./hello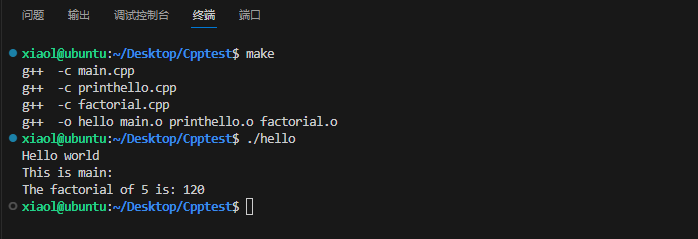
-
法三
# VERSION 3 CXX = g++ TARGET = hello OBJ = main.o printhello.o factorial.o# 编译选项,显示所有的warning CXXLAGS = -c -Wall# $@表示的就是冒号前面的TARGET,$^表示的是冒号后OBJ的全部.o依赖文件 $(TARGET): $(OBJ)$(CXX) -o $@ $^# $<表示指向%.cpp依赖的第一个,但是这里依赖只有一个 # $@表示指向%.o %.o: %.cpp$(CXX) $(CXXLAGS) $< -o $@# 为了防止文件夹中存在一个文件叫clean .PHONY: clean# -f表示强制删除,此处表示删除所有的.o文件和TARGET文件 clean:rm -f *.o $(TARGET)此时可以通过如下命令删除所有的.o文件和TARGET文件
make clean编译并运行
make ./hello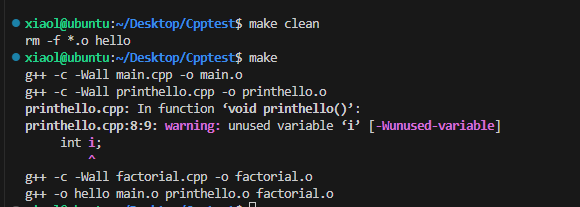
-
法四
# VERSION 4 CXX = g++ TARGET = hello # 所有当前目录的.cpp文件都放在SRC里面 SRC = $(wildcard *.cpp) # 把SRC里面的.cpp文件替换为.o文件 OBJ = $(patsubst %.cpp, %.o,$(SRC))CXXLAGS = -c -Wall$(TARGET): $(OBJ)$(CXX) -o $@ $^%.o: %.cpp$(CXX) $(CXXLAGS) $< -o $@.PHONY: clean clean:rm -f *.o $(TARGET)
cmake
CMakeLists.txt文件内容为:
project(SortMake)
aux_source_directory(src SRC_SUB)
aux_source_directory(. SRC_CUR)
add_executable(sort ${SRC_SUB} ${SRC_CUR})
include_directories(include)
project():设置项目名称,参数可以随意指定aux_source_directory(dir VAR):搜索dir目录下所有的源文件,并将结果列表存储在变量VAR中add_executable(target src): 指定使用源文件src,生成可执行程序target,${变量名}是取变量的值include_directories(headDir): 设置包含的头文件目录
编译并运行
cmake .
此时可以查看,cmake帮我们生成了Makefile文件
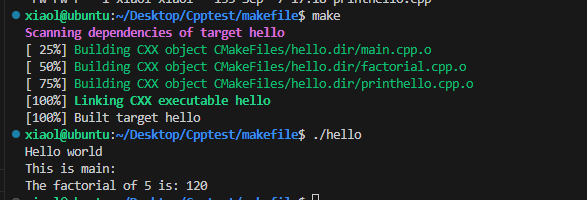
此时就可以不用自己写Makefile文件,直接用cmake生成了Makefile文件,然后编译并运行
由于cmake .后会生成许多中间文件,因此,我们可以建立一个build文件来存放这些中间文件。
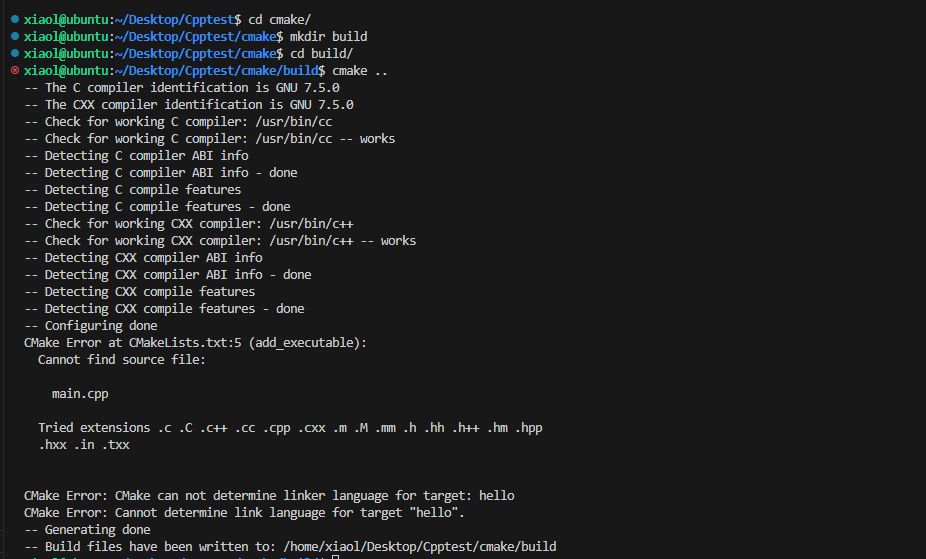
其中,cmake ..的意思是去上一层文件夹中找CMakeLists.txt文件
gdb代码调试入门
-
在程序中加入GDB调试信息
这儿以gcc编译工具为例,跟上“-g”则为加上了gdb调试信息,生成可执行程序gcc gdb.c -o gdb -g -
启动GDB工具
gdb + 可执行文件(带gdb调试信息)
-
在GDB工具中查看代码
list 代码所在行显示目标行数以后的代码,输入后继续按回车显示完所有代码,gdb自动记录上一条执行的语句。
list 函数名显示函数名对应的函数源代码
-
运行程序
可以简写为
rrun -
打断点
可以简写成
bbreak 函数名断点打在函数定义处,进入执行函数时停住
break 行数断电打在对应行,在指定行号前停住
break c文件名:行号在源文件filename的对应行号停住
break没有参数时,表示在下一条指令处停住
delete break删除所有断点,其中删除断点可以简写为
d。delete break 断点号删除指定断点,断点号由info中获得
clear 行号删除行对应的断点
disable 断点号使能断点,不会删除
-
单步调试
next单步执行,但遇到函数时不会进入函数中(next缩写为n)
next <count>单步执行,直接运行到当前行后count个指令,然后停住
step单步执行,会进入函数中(step缩写为s)
step <count>单步执行,直接运行到当前行后count个指令,然后停住
finish用于进入函数后退出函数,并打印函数返回时的堆栈地址,返回值即参数值等信息
until 行号执行到对应行号处停下,一般用于跳出循环(until缩写为u)
-
继续运行命令(continue缩写为c)
continue <ignore_break_count>恢复程序运行,直到程序结束或到达下一个断点,ignore_break_count表示跳过后面ignore_break_count多个断点。
-
查看当前程序运行的数据
显示变量(print缩写为p)print <expr> print /<f> <expr> -
当程序被停住时,可以使用print命令来查看程序运行的数据,是表达式或者变量,是输出的格式,如下。
x:按照16进制显示变量d:按照10进制显示变量u:按照16进制显示无符号整型o:按照8进制显示变量t:按照2进制显示变量a:按照16进制格式显示变量c:按字符串格式显示变量f:按浮点数格式显示变量
-
观察某个表达式或者变量
watch为表达式(变量)expr设置一个观察点,一旦值发生改变,程序马上停止运行,并打印出变量改变前后的值
rwatch当表达式(变量)expr被读时,停止程序运行
awatch当表达式(变量)expr被读或者被写时,停止程序运行
info watchpoints查看所有观察点
-
查看内存地址中的值(examine缩写为x)
examine/<n/f/u> addr -
gdb被从指定的内存地址开始,读写指定字节,并把其当作一个值取出来。
n:表示是一个正整数,表示显示的内存长度f:是显示的格式s:代表是显示字符串i:代表是显示指令地址x:按照16进制显示变量d:按照10进制显示变量u:按照16进制显示无符号整型o:按照8进制显示变量t:按照2进制显示变量a:按照16进制格式显示变量c:按字符串格式显示变量f:按浮点数格式显示变量u:表示从当前地址往后请求的字节数,不指定默认为4字节,其可以被b(表示单字节),h(表示双字节),w(表示四字 节),g(表示八字节)代替
-
取消未执行完的语句,直接返回
returnreturn <expression>expression是返回值,以该值返回
-
info命令
info break查看断点信息
info watchpoints查看所有观察点
info registers/info all-registers查看寄存器(r0等寄存器)