MySQL你必须知道的事
文章目录
- 前言
- 一、InnoDB的数据页,和B+树的关系?
- 二、为什么InnoDB三层B+树可以存2000w数据
- 三、什么是InnoDB的页分裂和页合并
- 四、什么是回表?怎么减少回表的次数?
- 什么是覆盖索引,索引下推?
- 覆盖索引
- 索引下推
- 总结
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、InnoDB的数据页,和B+树的关系?
InnoDB数据页是InnoDB存储引擎存储数据的基本单位。它在磁盘上是一个连续的区域,通常大小为16KB,也可以通过配置修改。16KB意味着InnoDB一次读写都是以16KB为单位的,磁盘到内存的读取,内存到磁盘的持久化都是16KB
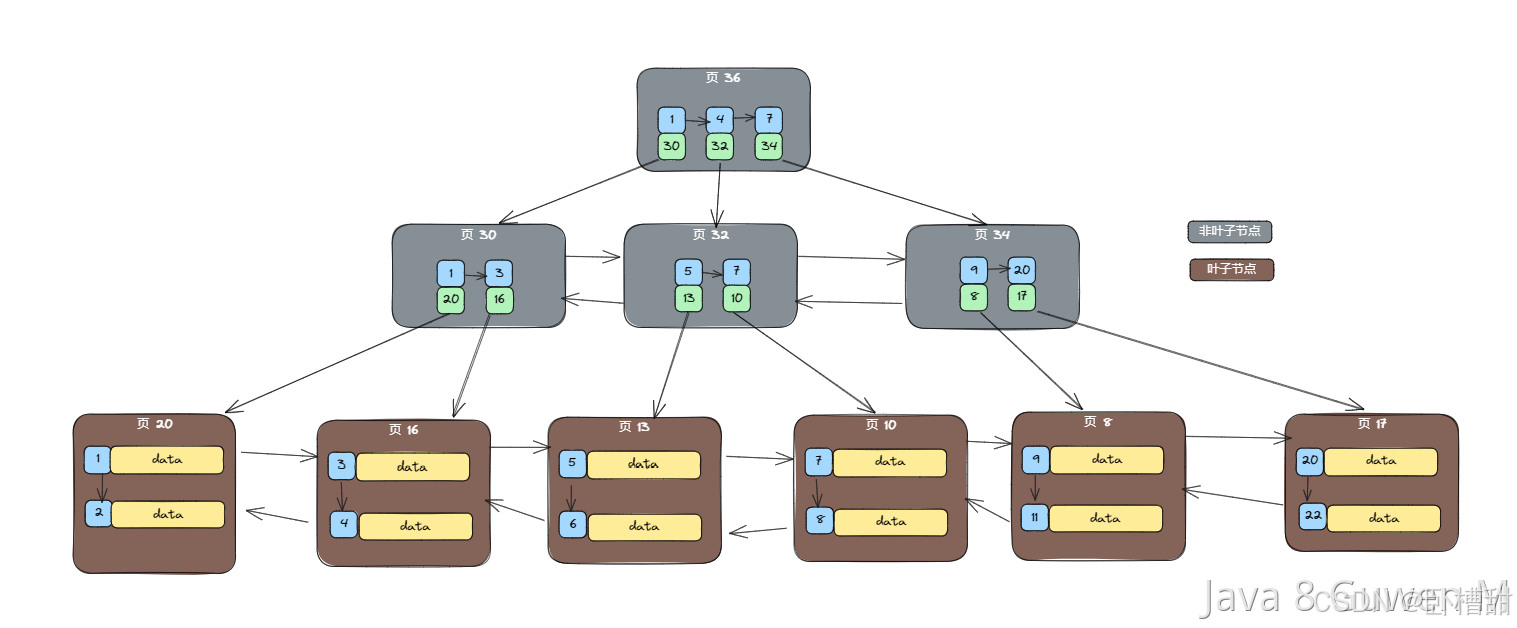
如图,非叶子节点存储的是主键id及页指针,叶子节点存的则是主键id和数据。如果是聚簇索引那么叶子节点就是主键id+整行数据,非聚簇索引叶子节点存的则是主键id+索引的值
二、为什么InnoDB三层B+树可以存2000w数据
由于InnoDB的一页大小是16KB如图,可以通过命令查看
show variables like ‘innodb_page_size’
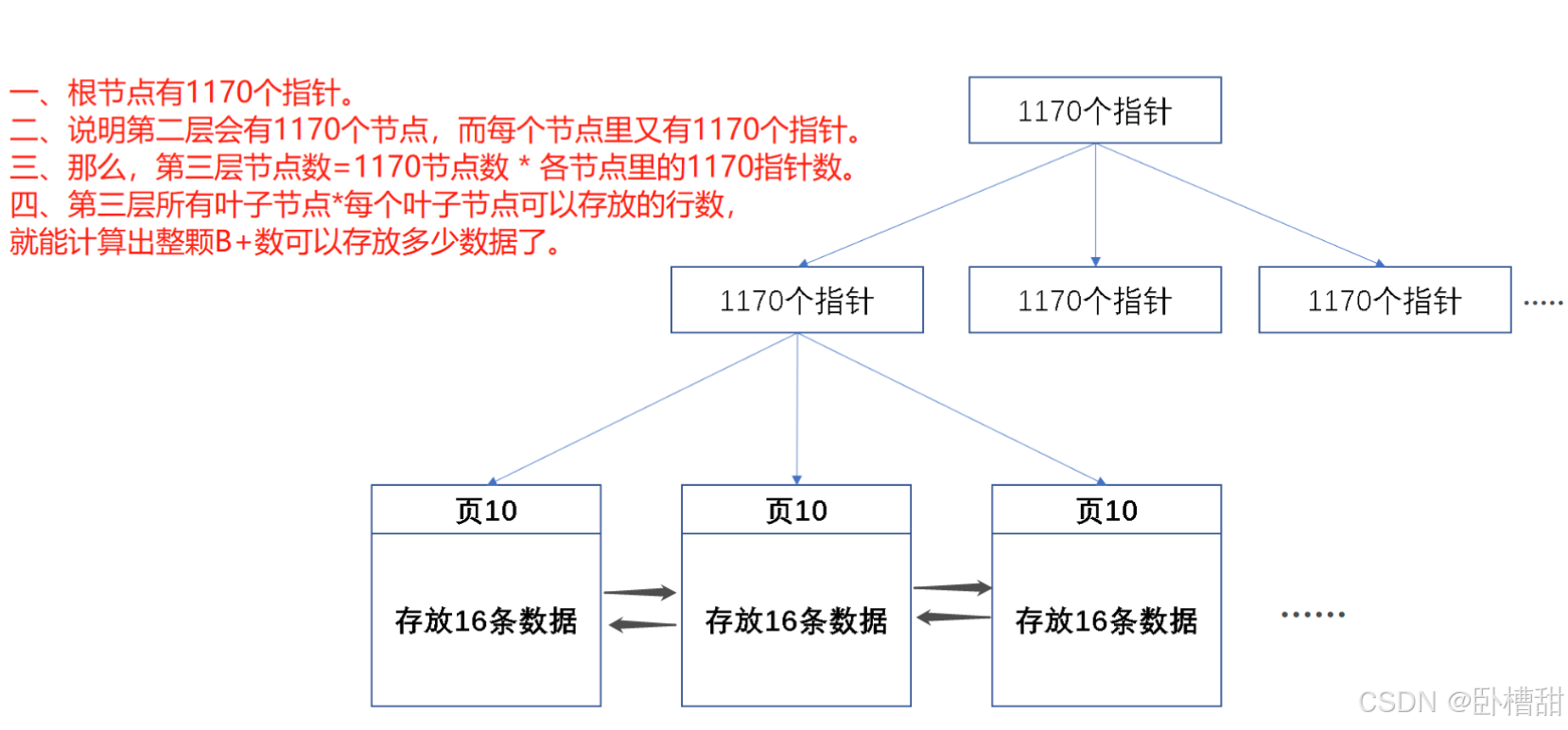
在通常情况下就算是宽表最坏情况按一行数据1KB计算,那么一页可以存16行数据,对于非叶子节点上面说过存的是主键索引和下一个节点的指针。假如是bigint类型的索引,占8字节,mysql数据库中指针大小为6字节,那么一页中一个指针会占用14字节,16KB=16384字节,即16384/14=1170。证明一页可以存1170个指针。对于三层B+树根节点有1170个子节点,每个子节点可以存1170页数据行,就是1170117016= 21902400,大约就是2000w数据
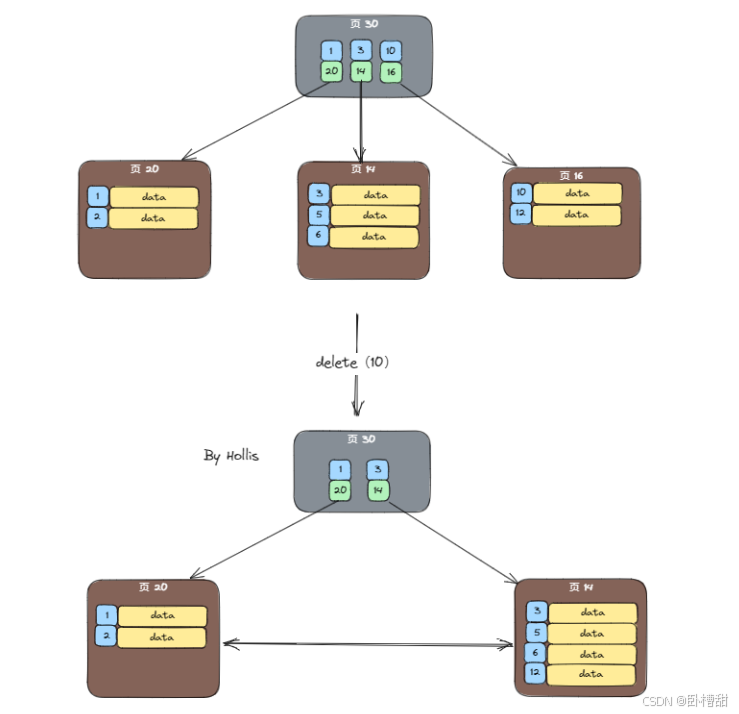
三、什么是InnoDB的页分裂和页合并
众所周知B+树是按照索引字段建立的,并且是有序的。但是如图索引字段的值并不连续
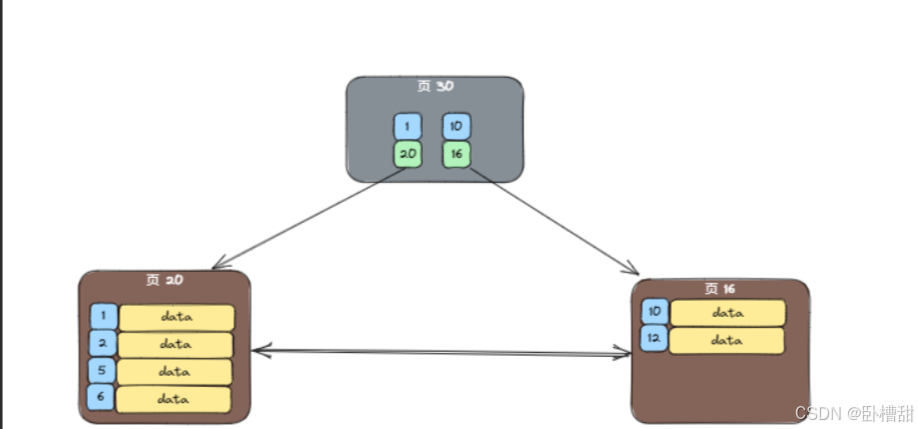
假如我们现在要插入索引值为3,按顺序它应该插入到页20中且在1,2之间,如果此时页20已经满了,就需要触发一次页分离
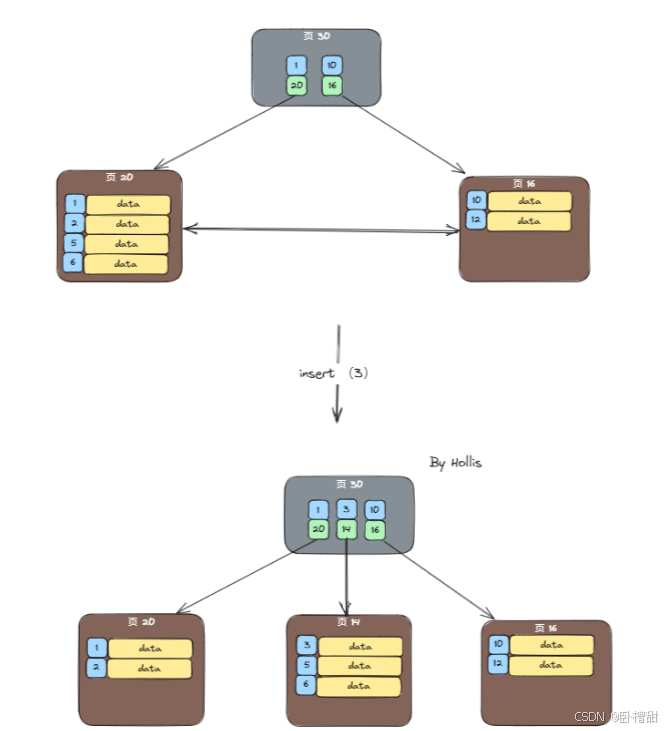
页分裂是指将该页面的一部分索引记录迁移到新页面中,从而为新索引记录腾出空间,以此保证B+树的平衡和性能
如图为一次分裂过程:
有分裂就会有合并。当索引页面有数据删除时会使页面变得稀疏,此时为了节省空间和提升性能,可能会触发页合并操作。
页合并是值将相邻两个页面合并为一个更大的页面,减少B+树层级,从而提高查询性能
如图为一次合并过程:
四、什么是回表?怎么减少回表的次数?
在InnoDB中,索引B+树叶子节点存储了整行数据的是主键索引即聚簇索引。如果叶子节点存储的是主键索引的值就是非聚簇索引。
当我们根据非主键索引查询时,会先通过非聚簇索引拿到主键的值,之后还要通过主键索引的值再次查询得到我们需要的数据,这就是回表
在InnoDB中通过主键索引查询效率是很高的,此过程不需要回表。另外依赖覆盖索引,索引下推等技术,我们也可以通过优化索引结构和sql语句来减少回表次数。
什么是覆盖索引,索引下推?
覆盖索引
指一个查询语句的执行只需要从索引中就能获得,不需要在从数据表中获取,避免了查到索引在返回表中操作,减少I/O提高效率。
如表A,有一个普通索引 idx_a1_a2(a1,a2)
select a2 from A where a1=‘xxx’;
此时就实现了覆盖索引,不需要回表。
但是如下sql
select a1 from A where a2=‘XXX’;
因为不符合最左前缀匹配,虽然是索引覆盖,但是也无法用到索引。
但是如果sql中的查询不包含在联合索引中,那么就不会走索引覆盖,如:
select a2,a3 from A where a1=‘xxx’;
索引下推
索引下推是MYSQL5.6引入的一种技术,默认开启。
先看样例表
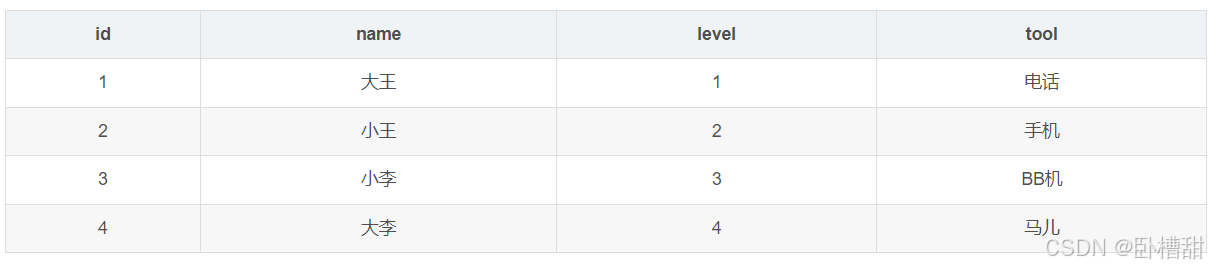
建立联合索引(name,level)
匹配姓名第一个字为“大”,并且level为1的用户,sql语句为
select * from user where name like “大%” and level = 1;
在5.6之前存储引擎先根据索引查询数据即通过name查到大王,大李。进行回表查询后返回给MySQL server层再筛选level=1的数据,回表次数为2。
5.6之后MySQL server会将索引列作为判断条件的传递给存储引擎。
即先查到大王,大李后筛选level=1,后在回表查询,次数为1
总结
如果没有索引下推优化(ICP优化)
首先根据索引查询记录,根据where过滤记录。
有了ICP优化,MySQL会取出索引的同时判断where条件是否能进一步过滤,在进行索引的查询。也就是说提前执行where的部分过滤操作,在某些场景下,可以大大减少回表次数,从而提升整体性能