Magic推出100M个token的上下文
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

目前,AI模型有两种学习方式:一种是通过训练,另一种是在推理过程中通过上下文学习。迄今为止,训练一直占据主导地位,因为模型处理的上下文通常比较短。然而,超长上下文可能会改变这一局面。
与依赖模糊记忆不同,Magic的长期记忆(LTM)模型在推理时可处理多达1亿个token的上下文,基于这些上下文进行推理。这种模型的商业应用十分广泛,但Magic专注于软件开发领域。
可以想象,如果模型在推理时能参考所有的代码、文档和库,甚至包括那些不在公共互联网上的资源,代码生成的效果将会显著提升。
评估上下文窗口
目前,关于长上下文的评估并不理想。广为人知的“干草堆中的针”评估方法,随机将一个事实(“针”)放在长上下文窗口(“干草堆”)的中间,要求模型提取该事实。

然而,如果一本关于鲸鱼的小说中出现“Arun和Max在Blue Bottle喝咖啡”这样的描述,它会显得格外突兀。模型能够识别出这种“不寻常”的信息,从而忽略干草堆中其他相关内容,减少存储负担。此外,模型只需关注上下文中一个小的、语义上显著的部分,这让像RAG这样的方法看起来很成功。
Mamba的第4.1.2节和H3的附录E.1中的归纳头基准使这一任务更加简单,它们使用特殊的token标记“针”的开始位置,大大降低了评估的存储和检索难度。这就像考前已经知道考试的题目一样。
这些细微的缺陷削弱了当前长上下文评估方法的有效性,使得传统的循环神经网络(RNN)和状态空间模型(SSM)即便受到O(1)大小的状态向量限制,依然能取得好成绩。
为了消除这些隐含和显式的语义提示,Magic设计了HashHop评估方法。
Hash是随机生成的,无法压缩,这意味着模型必须在任何上下文大小下存储并检索最大量的信息内容。
具体来说,Magic给训练有Hash的模型提示Hash对:
jJWlupoT → KmsFrnRa
vRLWdcwV → sVLdzfJu
YOJVrdjK → WKPUyWON
OepweRIW → JeIrWpvs
JeqPlFgA → YirRppTA接着,模型需要完成一个随机选定的Hash对:
完成 YOJVrdjK → WKPUyWON这评估了单步归纳头的出现情况,但实际应用通常需要多跳。因此,Magic要求模型完成一串Hash链条:
Hash 1 → Hash 2
Hash 2 → Hash 3
Hash 3 → Hash 4
Hash 4 → Hash 5
Hash 5 → Hash 6为了确保顺序和位置的不可变性,Magic将Hash对打乱后提示模型:
Hash 72 → Hash 81
Hash 4 → Hash 5
Hash 1 → Hash 2
...然后,要求模型完成:
完成 Hash 1 → Hash 2 Hash 3 Hash 4 Hash 5 Hash 6通过逐步写出所有中间的Hash值,这类似于“思维链”的推理方式,允许模型将推理过程延展至更长的时间。
Magic还提出了一个更具挑战性的变体,模型需要跳过步骤,直接完成:
完成 Hash 1 → Hash 6这要求模型架构能够一次性跨越整个上下文的多个点进行推理。
在对代码和语言模型进行评估时,Magic发现在Hash上训练小模型,并在这些简单任务上测量性能,是其架构研究的一个有效工具。
Magic的超长上下文进展
Magic最近训练了首个能处理1亿token上下文的模型:LTM-2-mini。1亿token相当于约1000万行代码或约750本小说。
每解码一个token,LTM-2-mini的序列维度算法在1亿token上下文窗口下比Llama 3.1 405B1的注意力机制便宜大约1000倍。
两者在内存需求上的差距更大——运行1亿token上下文的Llama 3.1 405B需要每个用户638个H100显卡来存储KV缓存,而LTM只需一块H100的很小一部分内存即可处理同样的上下文。
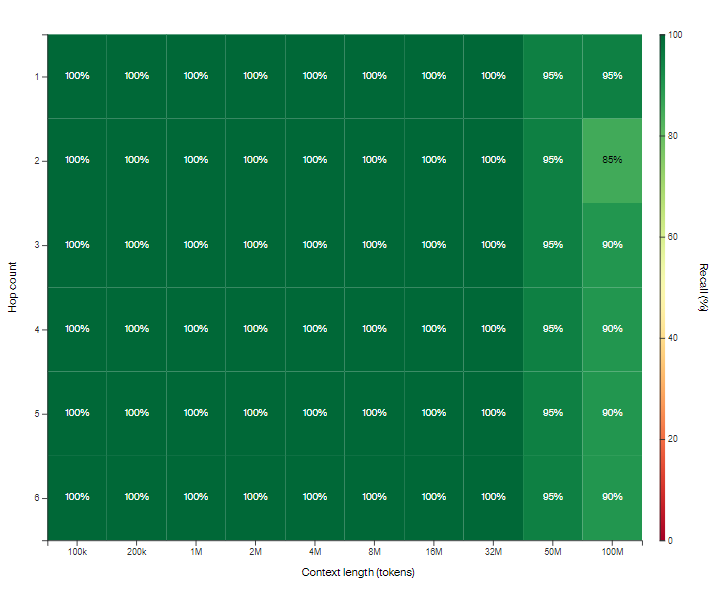
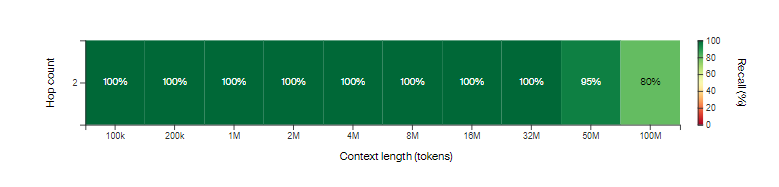
通过“思维链”训练的LTM架构在以下测试中取得了优异的表现,尽管在没有“思维链”的情况下,进行三次跳跃的表现有所下降,但两次跳跃时依然表现强劲,表明该模型能够构建比单一归纳头更复杂的逻辑回路。
此外,Magic还训练了一个原型模型,通过超长上下文机制进行文本到差异数据的训练。虽然该模型在代码生成方面还不如当今的前沿模型,但偶尔能产生合理的输出。
与Google Cloud合作打造NVIDIA超级计算机
Magic与Google Cloud和NVIDIA合作,正在构建两台新超级计算机:Magic-G4和Magic-G5,后者将搭载NVIDIA GB200 NVL72系统,可扩展至成千上万块Blackwell GPU。
Magic的联合创始人兼CEO Eric Steinberger表示,这一合作将大幅提升模型的推理和训练效率,帮助Magic快速扩展AI基础设施。Google Cloud和NVIDIA的强大硬件与软件生态,将助力Magic推动AI的下一次突破。