4.关于swintransformer
4.关于swintransformer
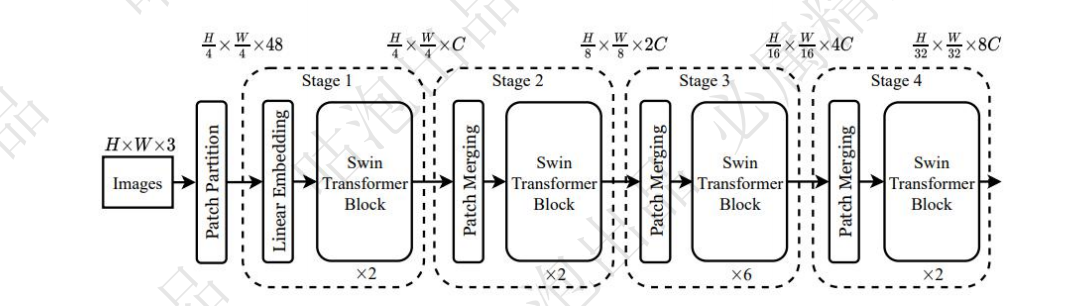
模型架构
swintransformer主要是在transformer的基础上引入类似于cnn的下采样,图片大小成倍减少,通道数成倍增加,使特征进行融合,减少了计算量
其次的特点就是使用W-MSA和SW-MSA,两个为一组来进行特征提取。引入窗口和分层机制,在进行下采样,多层叠加提取特征
Patch Partition
主要是将图片分成多个窗口,方便下一步,对每一个窗口进行embedding,形成每个窗口的多维向量
def forward(self, x): # ([4, 3, 224, 224])B, C, H, W = x.shape# FIXME look at relaxing size constraintsassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C 其中每个元素是96维向量 (4,4,96) 卷积print(x.shape) #4 3136 96 其中3136就是 224/4 * 224/4 相当于有这么长的序列,if self.norm is not None:x = self.norm(x)print(x.shape)return x
Linear Embedding
对上一步patch partition分成的每个窗口中的数据进行卷积,将每个窗口展开成多维度的向量
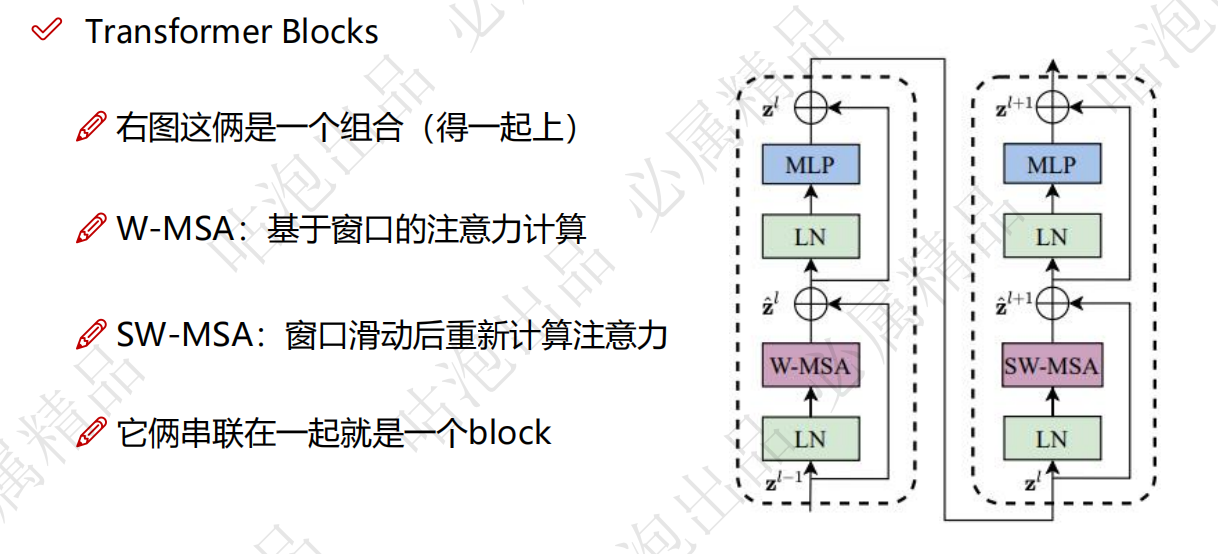
SwinTransformer Block
架构图
核心执行逻辑
class SwinTransformerBlock(nn.Module):def forward(self, x):H, W = self.input_resolution # 输入的分辨率高度和宽度B, L, C = x.shape # B是batch size, L是序列长度, C是通道数assert L == H * W, "input feature has wrong size" # 确保输入特征尺寸正确shortcut = x # 保存输入特征用于后续残差连接x = self.norm1(x) # 先进行规范化处理x = x.view(B, H, W, C) # 将输入变形为[B, H, W, C],方便后续操作# 循环移位(cyclic shift)if self.shift_size > 0: # 判断是否使用W-MSA或SW-MSAshifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) # 进行循环移位else:shifted_x = x # 如果shift_size为0,不进行移位# 分割窗口(partition windows)x_windows = window_partition(shifted_x, self.window_size) # 将图像分割为多个窗口,形状为[nW*B, window_size, window_size, C]x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # 调整形状为[nW*B, window_size*window_size, C]# 进行W-MSA或SW-MSAattn_windows = self.attn(x_windows, mask=self.attn_mask) # 对窗口进行自注意力计算,形状为[nW*B, window_size*window_size, C]# 合并窗口(merge windows)attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # 将注意力结果变回原窗口形状 (256,7,7,96)shifted_x = window_reverse(attn_windows, self.window_size, H, W) # 将窗口合并回原图像,形状为[B, H', W', C] ([4, 56, 56, 96])# 逆循环移位(reverse cyclic shift)if self.shift_size > 0: # 如果使用了移位,则逆向移位还原x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))print(x.shape) # 输出形状以便调试else:x = shifted_x # 如果没有移位,直接使用当前结果x = x.view(B, H * W, C) # 调整回原来的形状[B, L, C]print(x.shape) # 输出形状以便调试# 前馈神经网络(FFN)x = shortcut + self.drop_path(x) # 残差连接,并使用drop path防止过拟合print(x.shape) # 输出形状以便调试x = x + self.drop_path(self.mlp(self.norm2(x))) # 再次残差连接,并通过MLP进行非线性变换print(x.shape) # 输出形状以便调试return x # 返回最终结果关于window_partition
def window_partition(x, window_size):"""Args:x: (B, H, W, C)window_size (int): window sizeReturns:windows: (num_windows*B, window_size, window_size, C)"""B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)print(x.shape) # ([4, 8, 7, 8, 7, 96]) 4个batch,8 * 8 个窗口,每个窗口7*7的大小 每个点向量维度是96windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C) # window的数量 H/7 * W/7 *batchprint(windows.shape) # ([256, 7, 7, 96]) 将所有batch的窗口合并return windows
W-MSA和SW-MSA
W-MAS是窗口多头注意力机制,也就是说,每个窗口自己进行self-attention,经过LN和MLP进行特征提取,再交给SW-MSA进行处理
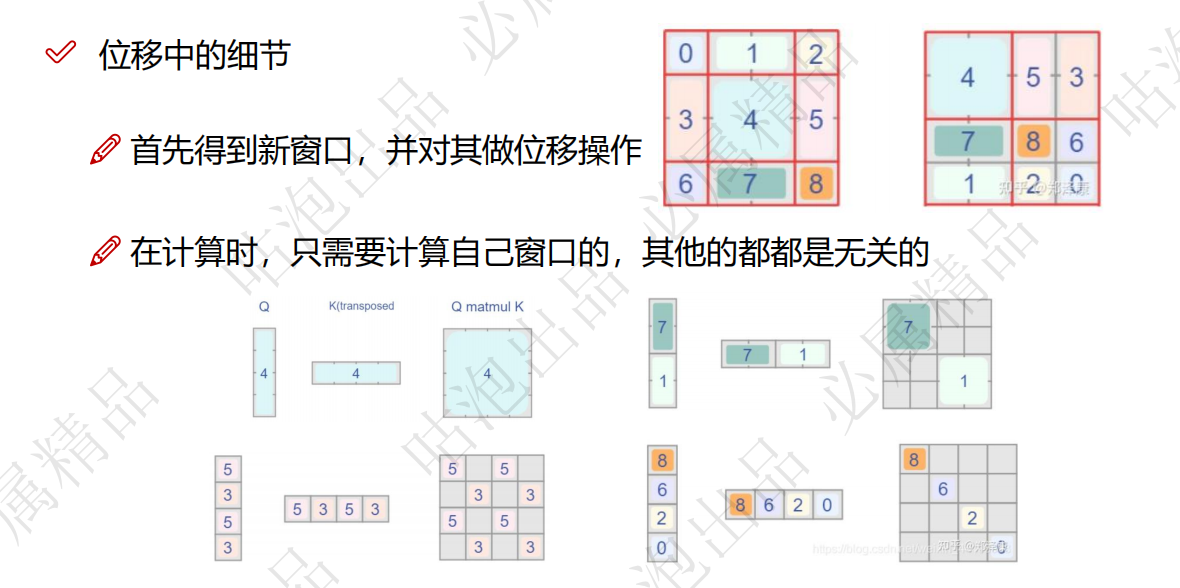
SW-MSA是滑动窗口多头注意力机制,再经过了W-MSA处理之后,将窗口滑动,这里涉及到窗口滑动之后,计算量增加的问题,使用mask机制,使得原来的计算量和之前是一样。SW-MSA使得窗口不仅仅可以学习到自己的特征,同时可以学习滑动后邻居的特征,使得特征的提取更加丰富。
class SwinTransformerBlock(nn.Module):def forward(self, x, mask=None):"""Args:x: 输入特征,形状为 (num_windows*B, N, C)mask: 可选的掩码 (0/-inf),形状为 (num_windows, Wh*Ww, Wh*Ww) 或 None"""B_, N, C = x.shape # B_是num_windows*B, N是窗口内的像素数, C是通道数# 计算查询、键、值矩阵qkvqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)print(qkv.shape) # 输出qkv形状 ([3, 256, 3, 49, 32]),即q、k、v三个矩阵,256个窗口,49个点,3个头,每个头32维度q, k, v = qkv[0], qkv[1], qkv[2] # 分别获取q、k、v矩阵print(q.shape) # 输出q的形状print(k.shape) # 输出k的形状print(v.shape) # 输出v的形状q = q * self.scale # 对q矩阵进行缩放# 计算注意力得分 (q和k的点积)attn = (q @ k.transpose(-2, -1))print(attn.shape) # 输出attn形状 ([256, 3, 49, 49]),即每一个点都与其他点计算注意力,得到49点的49个向量# 获取相对位置偏差relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # 形状为 Wh*Ww, Wh*Ww, nHprint(relative_position_bias.shape) # 输出相对位置偏差形状# 调整相对位置偏差的形状relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # 形状为 nH, Wh*Ww, Wh*Wwprint(relative_position_bias.shape) # 输出调整后的相对位置偏差形状# 将相对位置偏差添加到注意力得分中attn = attn + relative_position_bias.unsqueeze(0)print(attn.shape) # 输出加入位置偏差后的注意力得分形状# 如果提供了mask,则应用maskif mask is not None:nW = mask.shape[0] # 获取mask的窗口数attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn) # 对注意力得分应用softmaxelse:attn = self.softmax(attn) # 直接对注意力得分应用softmaxattn = self.attn_drop(attn) # 应用注意力dropoutprint(attn.shape) # 输出注意力得分形状# 计算attn和v的加权结果,得到最后的输出x = (attn @ v).transpose(1, 2).reshape(B_, N, C)print(x.shape) # 输出加权后的输出形状x = self.proj(x) # 应用线性投影print(x.shape) # 输出投影后的形状x = self.proj_drop(x) # 应用投影dropoutprint(x.shape) # 输出最终的形状return x # 返回最终结果mask机制
关于mask机制,其实就是,因为窗口滑动(实际上就是移动像素点),距离是确定的,这样我们可以通过矩阵运算和原来一样运算,只是有些运算结果是没有用的,使用mask将没有用的信息标注出来,使得计算量和W-MSA是一样的。
Patch Merging
对swinTransformer block结果进行下采样,但是这里下采样和cnn的池化是不一样的,是通过每隔一个单位去一个数据,一共可以取到4组数据,将四组数据叠在一起卷积。使用的卷积核个数是原来特征图个数的一半,使得通道数变为1/2,特征图变为原来的1/4。

class PatchMerging(nn.Module):def forward(self, x):"""x: 输入张量,形状为 (B, H*W, C)"""H, W = self.input_resolution # 获取输入的分辨率高度H和宽度WB, L, C = x.shape # B为批量大小,L为特征的长度(应为H*W),C为通道数assert L == H * W, "输入特征的尺寸不正确" # 确保输入的特征长度等于H*Wassert H % 2 == 0 and W % 2 == 0, f"输入的分辨率 ({H}*{W}) 不是偶数" # 确保输入的分辨率是偶数x = x.view(B, H, W, C) # 将输入张量重塑为 (B, H, W, C)# 将特征图分为四个部分x0 = x[:, 0::2, 0::2, :] # 取偶数行和偶数列的部分,形状为 (B, H/2, W/2, C)x1 = x[:, 1::2, 0::2, :] # 取奇数行和偶数列的部分,形状为 (B, H/2, W/2, C)x2 = x[:, 0::2, 1::2, :] # 取偶数行和奇数列的部分,形状为 (B, H/2, W/2, C)x3 = x[:, 1::2, 1::2, :] # 取奇数行和奇数列的部分,形状为 (B, H/2, W/2, C)# 将四个部分在最后一个维度上连接,得到 (B, H/2, W/2, 4*C)x = torch.cat([x0, x1, x2, x3], -1)x = x.view(B, -1, 4 * C) # 将张量重塑为 (B, H/2*W/2, 4*C)x = self.norm(x) # 对张量进行归一化处理x = self.reduction(x) # 进行通道数的缩减处理return x # 返回最终的输出
经过多次叠加,完成特征提取
class SwinTransformer(nn.Module):# ...# build layers,初始化BasicLayerself.layers = nn.ModuleList()for i_layer in range(self.num_layers):layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),input_resolution=(patches_resolution[0] // (2 ** i_layer),patches_resolution[1] // (2 ** i_layer)),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,mlp_ratio=self.mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,use_checkpoint=use_checkpoint)self.layers.append(layer)# ...class BasicLayer(nn.Module):# ...def forward(self, x):# 遍历每一个块(block)for blk in self.blocks:if self.use_checkpoint: # 如果启用了检查点机制x = checkpoint.checkpoint(blk, x) # 使用检查点保存内存,并执行当前块的前向计算else:x = blk(x) # 直接执行当前块的前向计算# 如果定义了下采样模块,则执行下采样操作if self.downsample is not None:x = self.downsample(x)return x # 返回最终的输出0