网络层IP协议
文章目录
- 网络层IP协议
- 1、概念
- 2、IP协议
- 2.1、IP协议格式
- 2.2、网段划分
- 2.3、CIDR 无类别域间路由
- 2.4、特殊的 IP 地址
- 2.5、IPv6
- 2.6、私有 IP 地址和公网 IP 地址
- 2.7、路由
- 2.8、路由表生成算法

网络层IP协议
1、概念
网络层是OSI模型的第三层,它负责数据包在网络中的路由选择和转发。它的主要功能是确定数据从源到目的地的最佳路径,并在多个网络之间转发数据。
简单来说就是网络层IP协议的作用就是在复杂的网络环境中确定一个合适的路径。
- 主机:配有 IP 地址,但是不进行路由控制的设备
- 路由器:即配有 IP 地址,又能进行路由控制
- 节点:主机和路由器的统称
2、IP协议
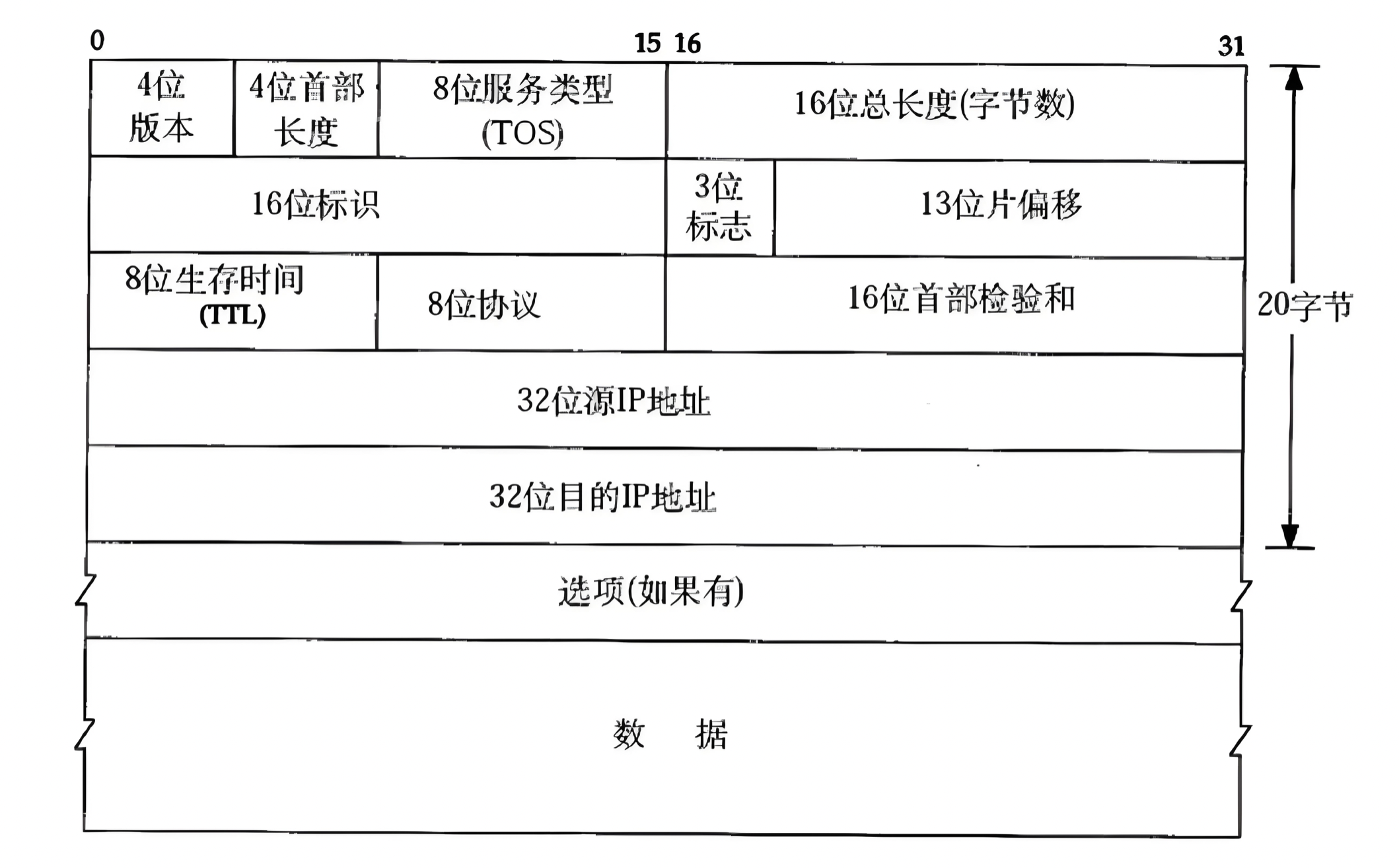
2.1、IP协议格式
- 版本(Version):4位
表示IP协议的版本号。对于IPv4协议,这个值为4。
- 头部长度(IHL, Internet Header Length):4位
表示IP头部的长度,以32位(4字节)为单位。最小值为5,即头部长度为20字节。
- 服务类型(Type of Service, TOS):8位
表示服务质量要求。它包括用于优先级、延迟、吞吐量、可靠性等服务质量的指定。
- 总长度(Total Length):16位
表示整个IP数据报的长度(包括头部和数据),单位为字节。最大长度为65,535字节。
- 标识(Identification):16位
唯一标识发送主机发送的每个数据报,用于分片和重组数据报。
- 标志(Flags):3位
用于控制和标识分片数据报。包括是否允许分片、是否为最后一个分片等。
- 片偏移(Fragment Offset):13位
表示当前片段在原始数据报文中的位置,用于数据报重组。
- 生存时间(TTL, Time to Live):8位
指定数据报可以经过的最大跳数,每经过一个路由器,TTL值减1,当TTL值减到0时,数据报将被丢弃,防止数据报在网络中无限循环。
- 协议(Protocol):8位
表示封装在IP数据报中的上层协议类型。例如,6表示TCP协议,17表示UDP协议。
- 头部校验和(Header Checksum):16位
对IP头部进行错误检查,确保数据传输的完整性。
- 源地址(Source Address):32位
表示数据报的发送者的IP地址。
- 目标地址(Destination Address):32位
表示数据报的接收者的IP地址。
- 选项(Options):可变长度,最多为40字节
用于支持各种控制功能,通常不使用。
- 填充(Padding):可变长度
为了确保IP头部长度是4字节的整数倍,用于填充空位。
2.2、网段划分
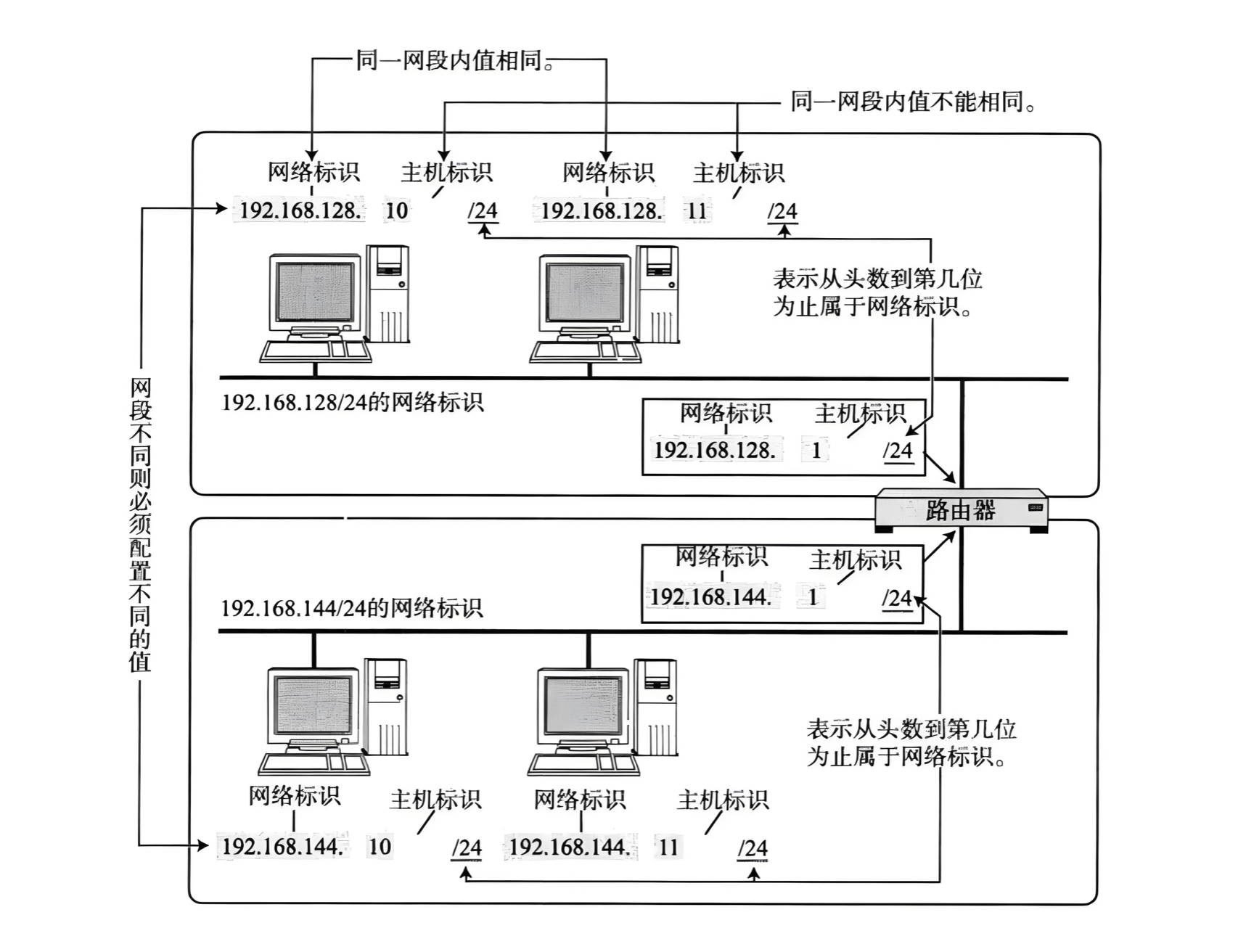
IP 地址分为两个部分,网络号和主机号。
网络号:保证相互连接的两个网段具有不同的标识
主机号:同一网段内,主机之间具有相同的网络号,但是必须有不同的主机号
- 不同的子网其实就是把网络号相同的主机放到一起。
- 如果在子网中新增一台主机,则这台主机的网络号和这个子网的网络号一致,但是主机号必须不能和子网中的其他主机重复。
通过合理设置主机号和网络号,就可以保证在相互连接的网络中,每台主机的 IP 地址都不相同。
那怎么管理(分配或者回收)子网的所有 IP 呢?
有一种技术叫做 DHCP(动态地址分配),能够自动的给子网内新增主机节点分配 IP 地址,避免了手动管理 IP 的不便。
一般的路由器都带有 DHCP 功能。因此路由器也可以看做一个 DHCP 服务器。
TCP/IP的设计者提出一种划分网络号和主机号的方案,把所有 IP 地址分为五类:
随着 Internet 的飞速发展,这种划分方案的局限性很快显现出来,大多数组织都申请 B 类网络地址,导致 B 类地址很快就分配完了,而 A 类却浪费了大量地址。
例如,申请了一个 B 类地址,理论上一个子网内能允许 6 万 5 千多个主机。A 类地址的子网内的主机数更多。
然而实际网络架设中,不会存在一个子网内有这么多的情况。因此大量的 IP 地址都被浪费掉了。
针对这种情况提出了新的划分方案,称为 CIDR(Classless Interdomain Routing,无类别域间路由)。

2.3、CIDR 无类别域间路由
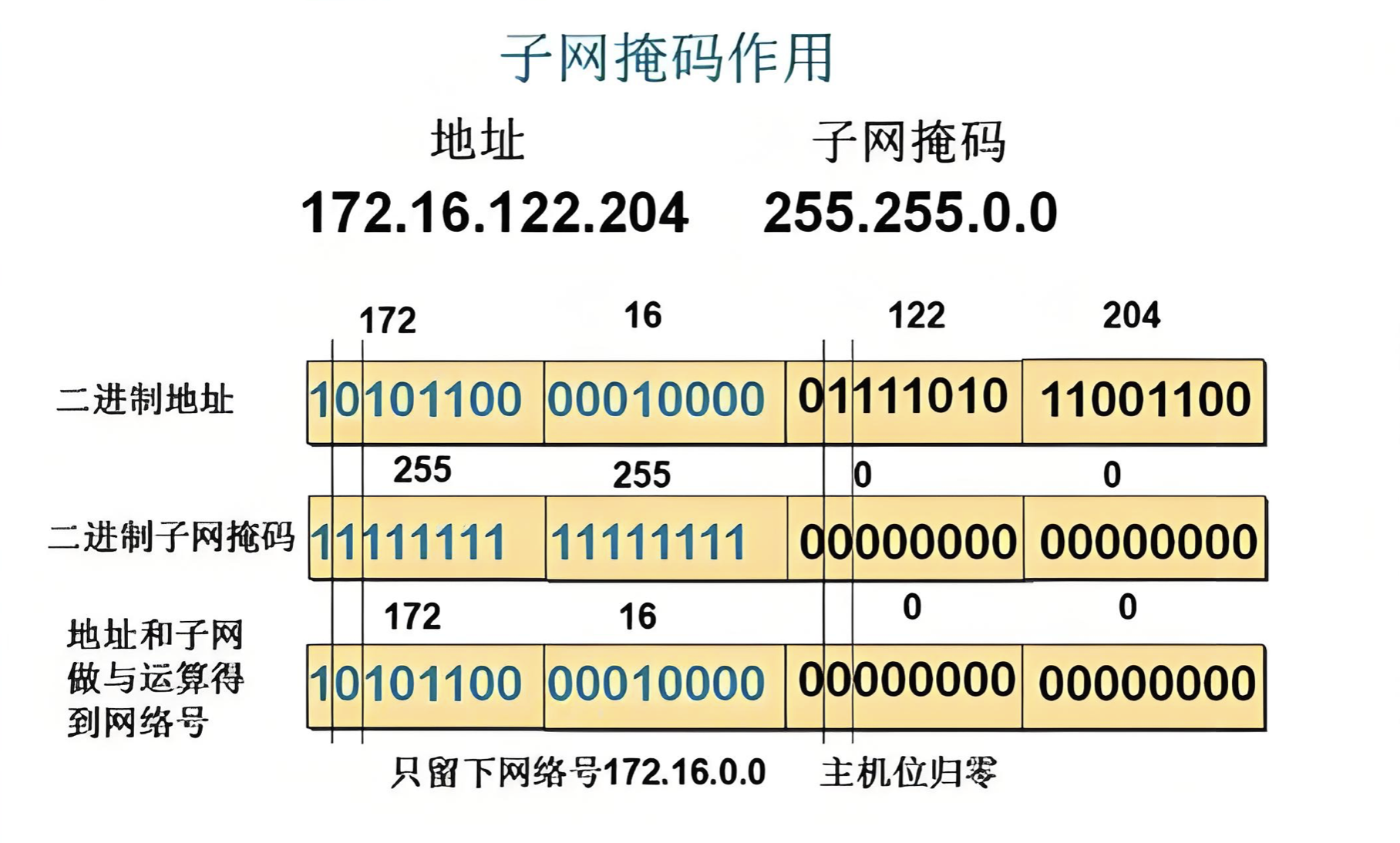
引入一个额外的子网掩码(subnet mask)来区分网络号和主机号
子网掩码也是一个 32 位的正整数,通常用一串 “0” 来结尾
将 IP 地址和子网掩码进行 “按位与” 操作,得到的结果就是网络号
这样,网络号和主机号的划分与这个 IP 地址是 A 类、B 类还是 C 类无关
可见,IP 地址和子网掩码做运算可以得到网络号,主机号从全 0 到全 1 就是子网的地址范围。
IP 地址和子网掩码还有一种更简洁的表示方法,例如 172.16.122.204/16 ,表示 IP 地址为 172.16.122.204,子网掩码的高 16 位是 1 ,也就是 255.255.0.0。
2.4、特殊的 IP 地址
将 IP 地址中的主机地址全部设为 0 ,就成为了网络号,代表这个局域网。
将 IP 地址中的主机地址全部设为 1,就成为了广播地址,用于给同一个链路(同一局域网)中相互连接的所有主机发送数据包。
127.* 的 IP 地址用于本机环回(loop back)测试,通常是 127.0.0.1。

2.5、IPv6
上面所有内容都是基于 IPv4 协议下的。
我们知道,IP 地址(IPv4)是一个 4 字节 32 位的正整数。那么一共只有 2 的 32 次方 个 IP地址,大概是 43 亿左右。而 TCP/IP 协议规定,每个主机都需要有一个 IP 地址。这意味着,一共只有 43 亿台主机能接入网络么?
实际上,由于一些特殊的 IP 地址的存在,数量远不足 43 亿。另外 IP 地址并非是按照主机台数来配置的,而是每一个网卡都需要配置一个或多个 IP 地址。CIDR 在一定程度上缓解了 IP 地址不够用的问题(提高了利用率,减少了浪费,但是 IP地址的绝对上限并没有增加),仍然不是很够用。这时候有三种方式来解决:
动态分配 IP 地址:只给接入网络的设备分配 IP 地址。因此同一个 MAC 地址的设备,每次接入互联网中,得到的 IP 地址不一定是相同的。
NAT 技术(后面会重点介绍)
IPv6:IPv6 并不是 IPv4 的简单升级版。这是互不相干的两个协议,彼此并不兼容,IPv6 用 16 字节 128 位来表示一个 IP 地址。但是目前 IPv6 还没有普及,但是国内知名科技公司一般使用用上了。

2.6、私有 IP 地址和公网 IP 地址
如果一个组织内部组建局域网,IP 地址只用于局域网内的通信,而不直接连到 Internet 上,理论上使用任意的 IP 地址都可以,但是 RFC 1918 规定了用于组建局域网的私有 IP 地址:
10.*,前 8 位是网络号,共 16,777,216 个地址172.16.*到172.31.*,前 12 位是网络号,共 1,048,576 个地址192.168.*,前 16 位是网络号,共 65,536 个地址包含在这个范围中的,都成为私有 IP ,其余的则称为全局 IP(或公网 IP)。
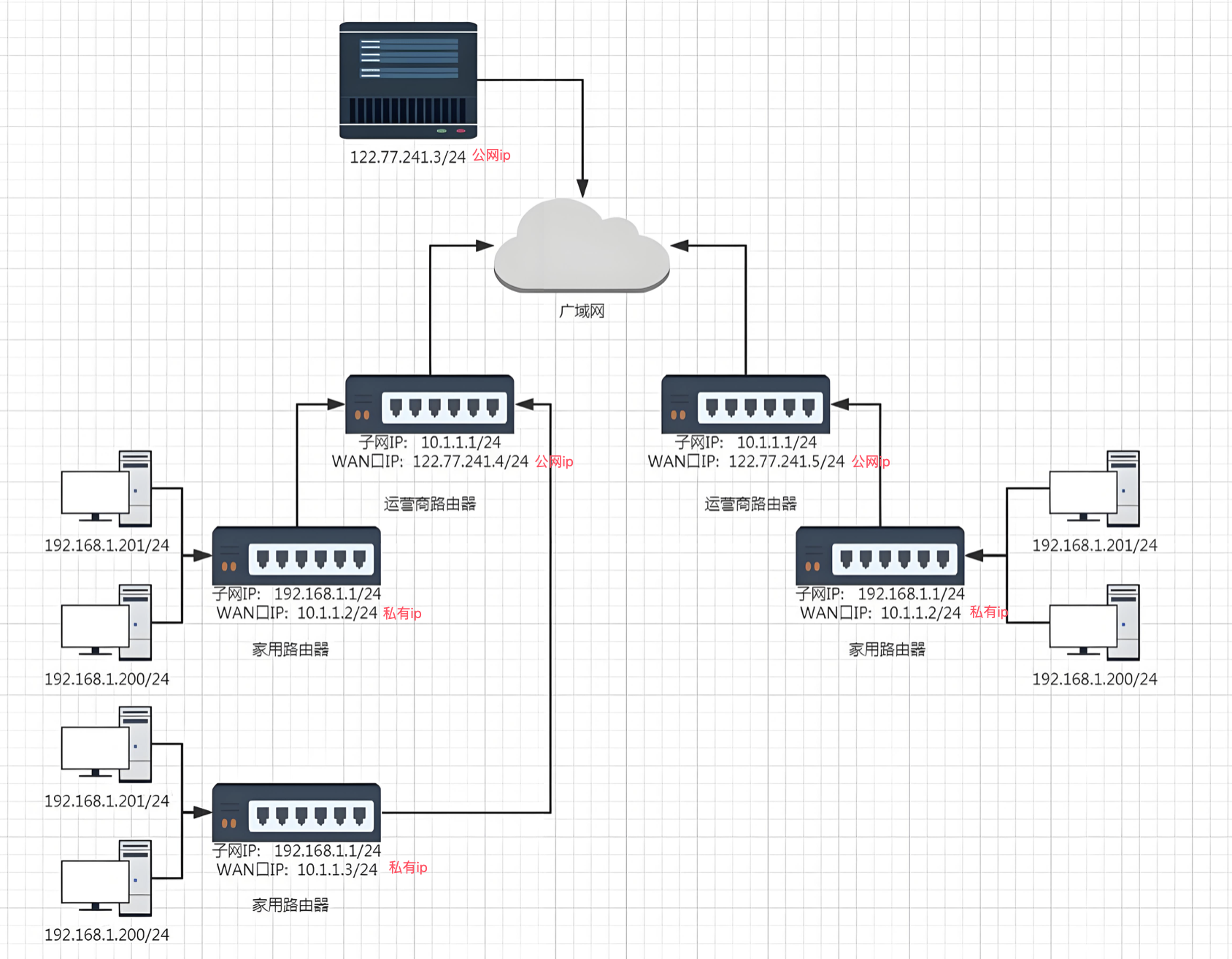
一个路由器可以配置两个 IP 地址,一个是 WAN 口 IP,一个是 LAN 口 IP(子网IP)。
路由器 LAN 口连接的主机,都从属于当前这个路由器的子网中。不同的路由器,子网 IP 其实都是一样的(通常都是192.168.1.1),因为我们用的路由器,也属于局域网,不同局域网的路由器 IP 一样没关系。
子网内的主机 IP 地址不能重复。但是子网之间的 IP 地址就可以重复了。
每一个家用路由器,其实又作为运营商路由器的子网中的一个节点。这样的运营商路由器可能会有很多级。最外层的运营商路由器,WAN 口 IP 就是一个公网 IP 了。
子网内的主机需要和外网进行通信时,路由器将 IP 首部中的 IP 地址进行替换(替换成 WAN 口 IP),这样逐级替换,最终数据包中的 IP 地址成为一个公网 IP。这种技术称为 NAT(Network Address Translation,网络地址转换)。
如果希望我们自己实现的服务器程序,能够在公网上被访问到,就需要把程序部署在一台具有外网 IP 的服务器上。这样的服务器可以在阿里云/腾讯云上进行购买。
2.7、路由
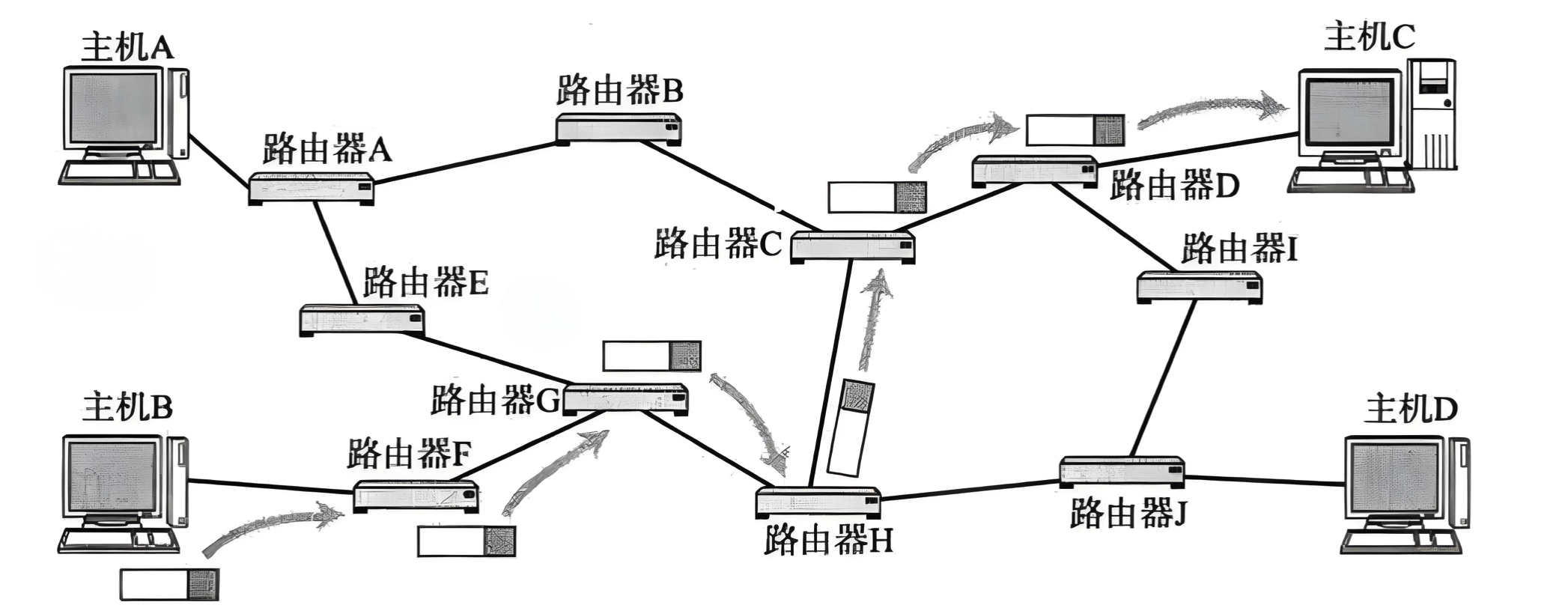
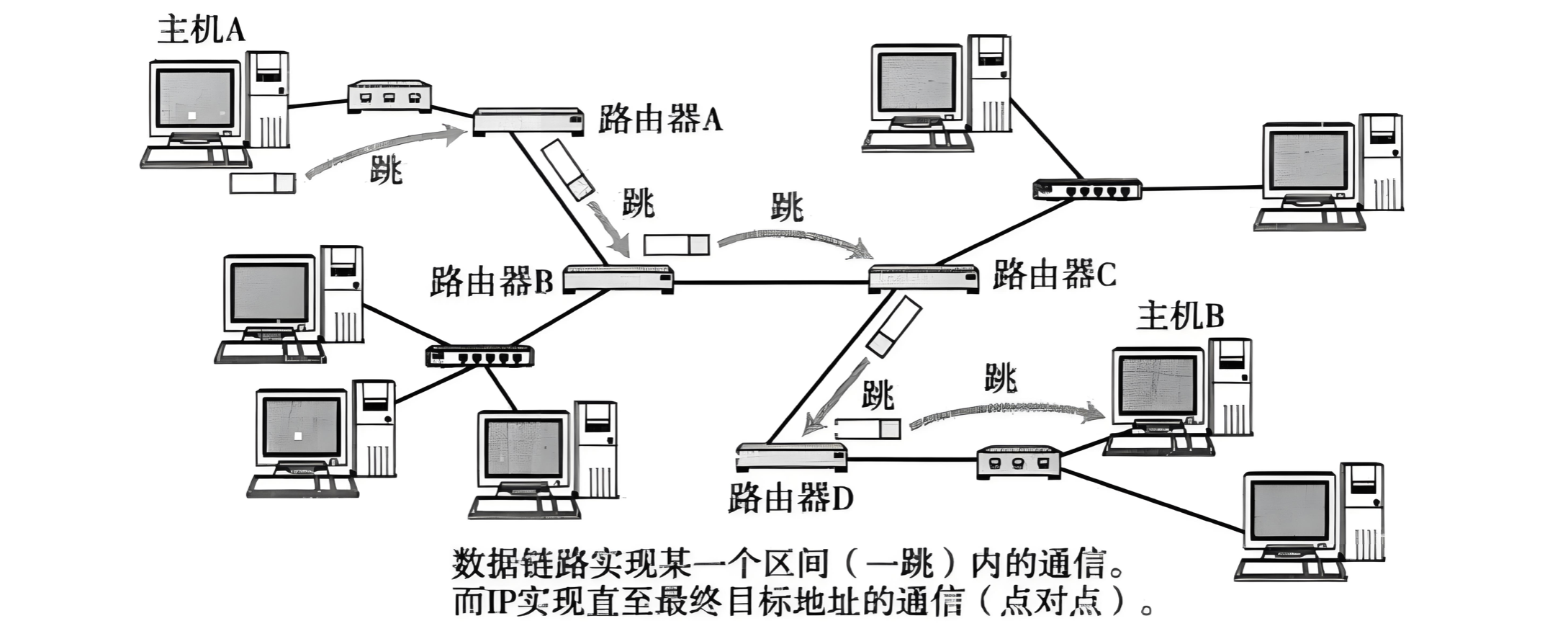
用下面这张图来解释吧。
- IP 数据包的传输过程和问路一样
- 当 IP 数据包到达路由器时,路由器会先查看目的 IP
- 路由器决定这个数据包是能直接发送给目标主机,还是需要发送给下一个路由器(使用子网掩码计算后查看是否属于这个网络)
- 依次反复,一直到达目标 IP 地址
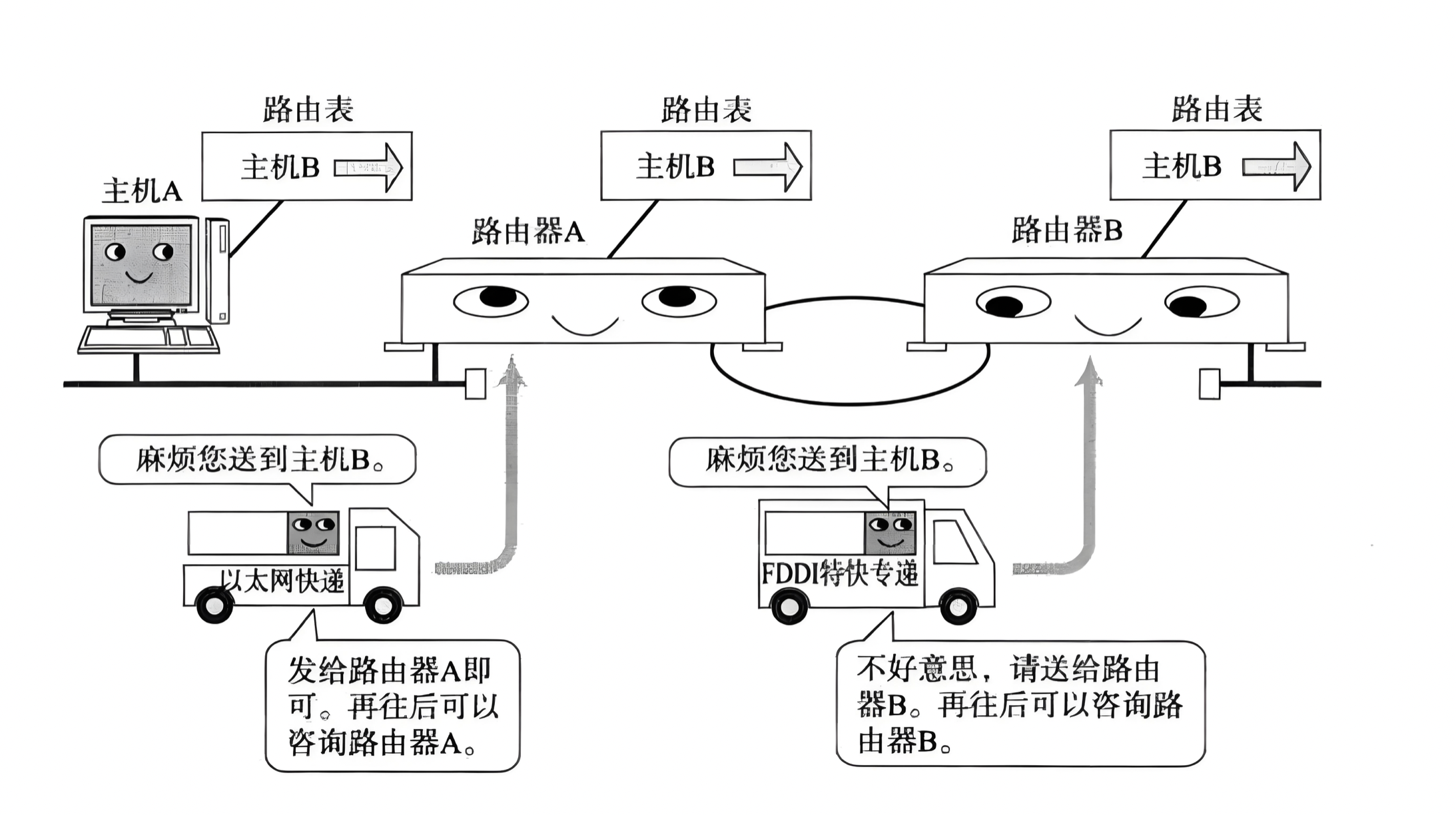
怎么确定当前这个数据包该发送到哪里呢? 这个就依靠每个节点内部维护一个路由表。
- 路由表可以使用 route 命令查看
- 如果目的 IP 命中了路由表(子网掩码计算后网络号就是该子网),就直接转发即可
- 路由表中的最后一行,主要由下一跳地址和发送接口两部分组成,当目的地址与路由表中其它行都不匹配时,就按缺省路由条目规定的接口发送到下一跳地址。
假设某台主机的路由表如下:
- 这台主机有两个网络接口,一个网络接口连到 192.168.10.0/24 网络
- 另一个网络接口连到 192.168.56.0/24 网络
- 路由表的 Destination 是目的网络地址,Genmask 是子网掩码,Gateway 是下一跳地址,Iface 是发送接口,Flags 中的 U 标志表示此条目有效(可以禁用某些条目),G 标志表示此条目的下一跳地址是某个路由器的地址,没有 G 标志的条目表示目的网络地址是与本机接口直接相连的网络,不必经路由器转发。
转发过程:
- 例 1:如果要发送的数据包的目的地址是 192.168.56.3
跟第一行的子网掩码做与运算得到 192.168.56.0,与第一行的目的网络地址不符
再跟第二行的子网掩码做与运算得到 192.168.56.0,正是第二行的目的网络地址,因此从 eth1 接口发送出去,由于 192.168.56.0/24 正是与 eth1 接口直接相连的网络,因此可以直接发到目的主机,不需要经路由器转发
- 例 2:如果要发送的数据包的目的地址是 202.10.1.2
- 依次和路由表前几项进行对比,发现都不匹配
- 按缺省路由条目,从 eth0 接口发出去,发往 192.168.10.1 路由器
- 由 192.168.10.1 路由器根据它的路由表决定下一跳地址

2.8、路由表生成算法
- 距离向量算法(Distance Vector Algorithm)
- 概述:距离向量算法,也称为Bellman-Ford算法,是一种动态路由算法。每个路由器都维护一张路由表,表中记录着到达网络中每个目的地的最佳路径及其距离(跳数)。
- 工作原理:路由器周期性地向其相邻路由器广播自己的路由表信息,包括已知的目的地及其距离。相邻路由器根据收到的信息更新自己的路由表,以确保路由表始终反映到达各目的地的最短路径。
- 优缺点:算法简单,易于实现,但存在慢收敛问题和可能产生路由循环的缺点。
- 链路状态算法(Link State Algorithm)
- 概述:链路状态算法,也称为最短路径优先算法(SPF,Shortest Path First),是另一种动态路由算法。
- 工作原理:每个路由器首先向网络中的其他路由器发送链路状态信息(如链路的成本和状态)。然后,每个路由器根据收集到的链路状态信息构建一个完整的网络拓扑图,并使用Dijkstra算法等算法计算到达每个目的地的最短路径。
- 优缺点:链路状态算法收敛速度较快,不易产生路由循环,但需要更多的CPU和内存资源,且实现相对复杂。
- Dijkstra算法
- 概述:Dijkstra算法是一种用于寻找图中节点间最短路径的算法,它常被用于链路状态算法中计算最短路径。
- 工作原理:算法从源节点开始,逐步扩展搜索范围,直到找到到达所有其他节点的最短路径。在搜索过程中,算法使用优先队列(或类似数据结构)来维护待考察的节点,并根据当前已知的最短路径长度进行排序。
- 特点:Dijkstra算法能够确保找到从源节点到所有其他节点的最短路径,且算法复杂度相对较低。
OKOK,网络层IP协议就到这里,如果你对Linux和C++也感兴趣的话,可以看看我的主页哦。下面是我的github主页,里面记录了我的学习代码和leetcode的一些题的题解,有兴趣的可以看看。
Xpccccc的github主页